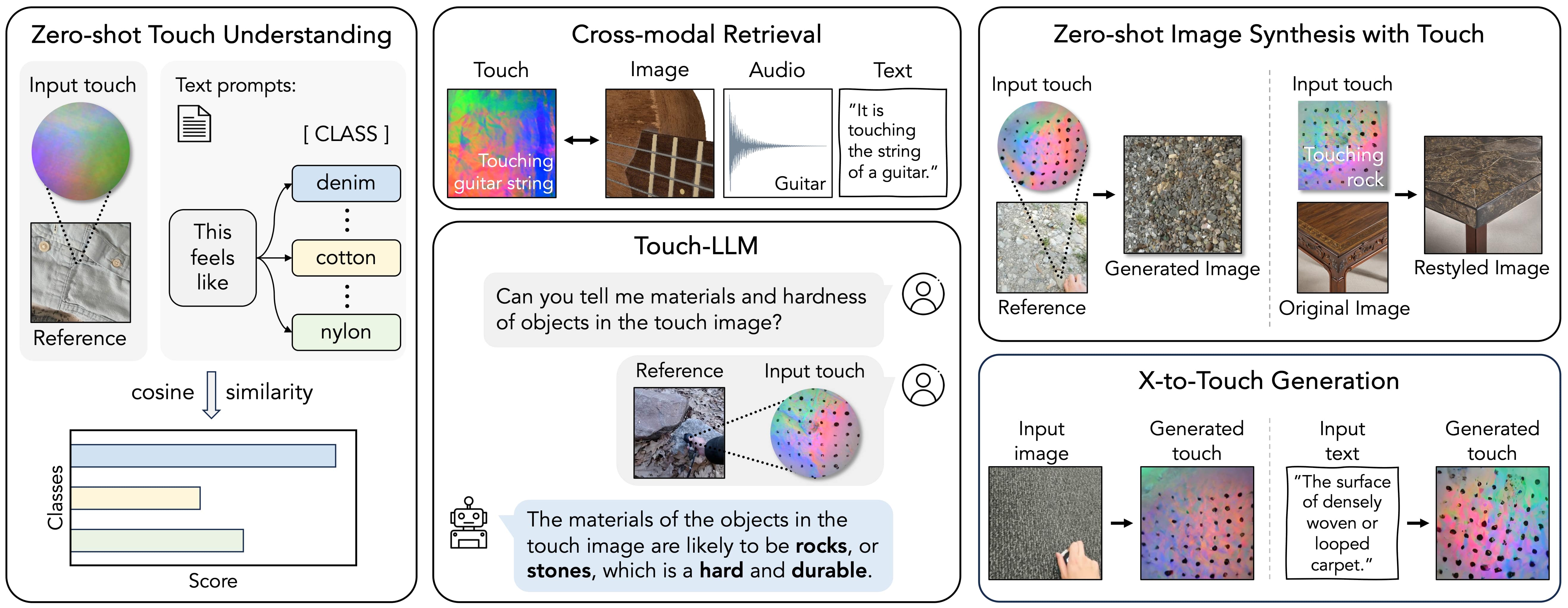
Our UniTouch can solve a variety of sensing tasks, ranging from touch image understanding to image synthesis with touch, in zero-shot manners.
The ability to associate touch with other modalities has huge implications for humans and computational systems. However, multimodal learning with touch remains challenging due to the expensive data collection process and non-standardized sensor outputs. We introduce UniTouch, a unified tactile model for vision-based touch sensors connected to multiple modalities, including vision, language and sound. We achieve this by aligning our UniTouch embeddings to pretrained image embeddings already associated with a variety of other modalities. We further propose learnable sensor-specific tokens, allowing the model to learn from a set of heterogeneous tactile sensors, all at the same time. UniTouch is capable of conducting various touch sensing tasks in the zero-shot setting, from robot grasping prediction to touch image question and answering. To the best of our knowledge, UniTouch is the first to demonstrate such capabilities.
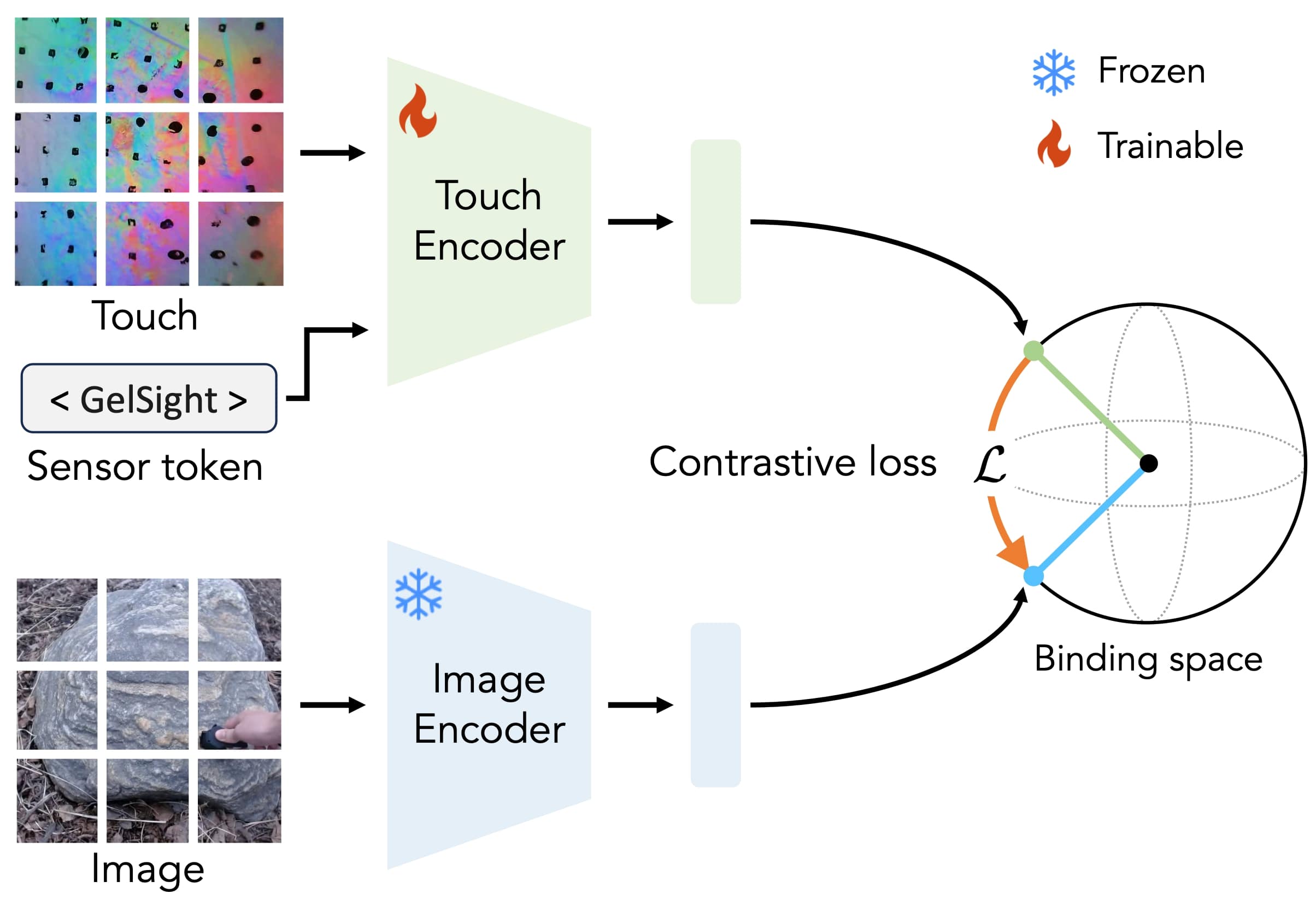
We align our touch embedding with a pre-trained image embedding derived from large-scale vision language data, using sensor-specific tokens for multi-sensor training.
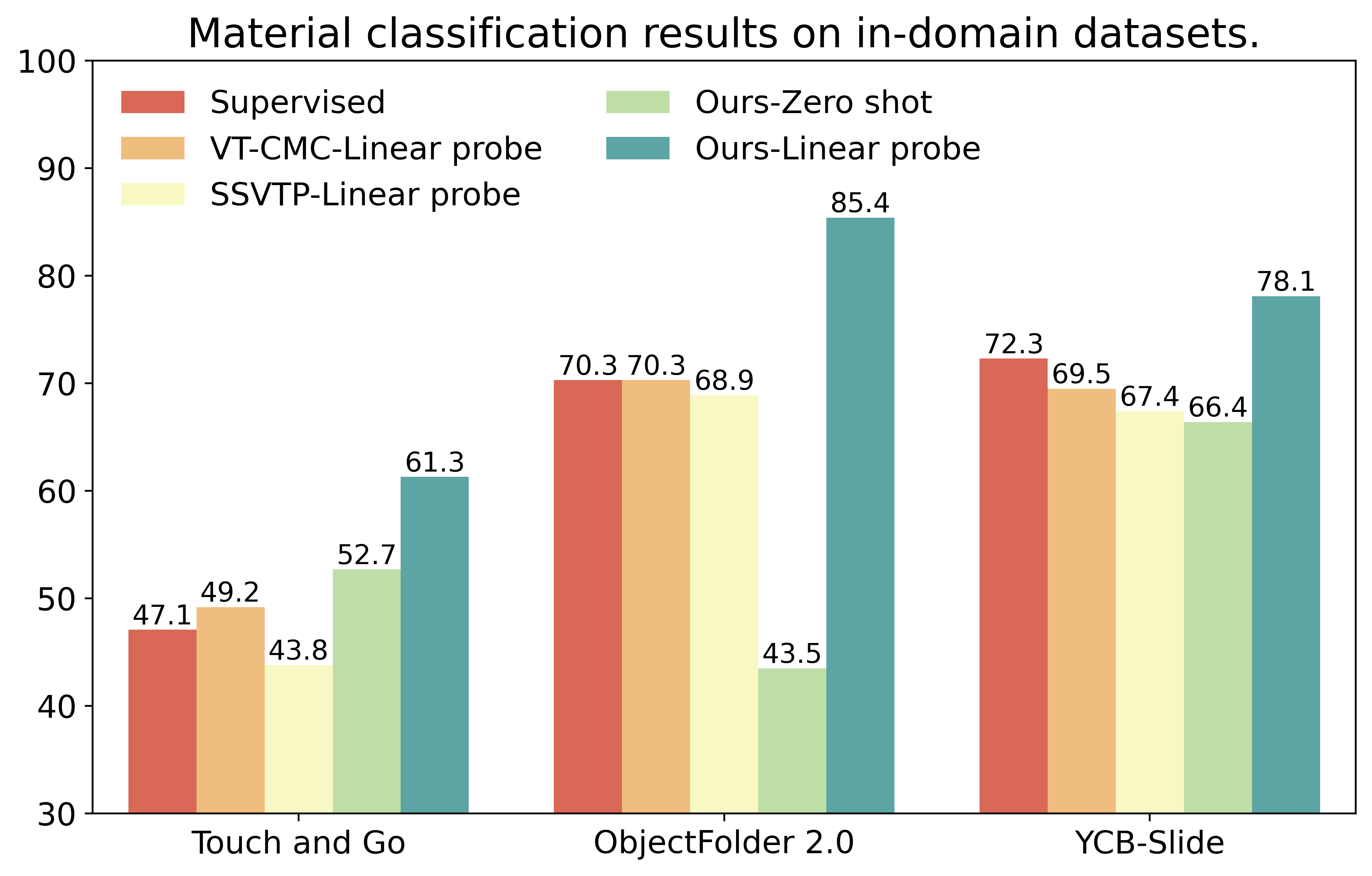
We learn an unified multimodal tactile representation for multiple touch sensors and it enables zero-shot touch understanding via languages.

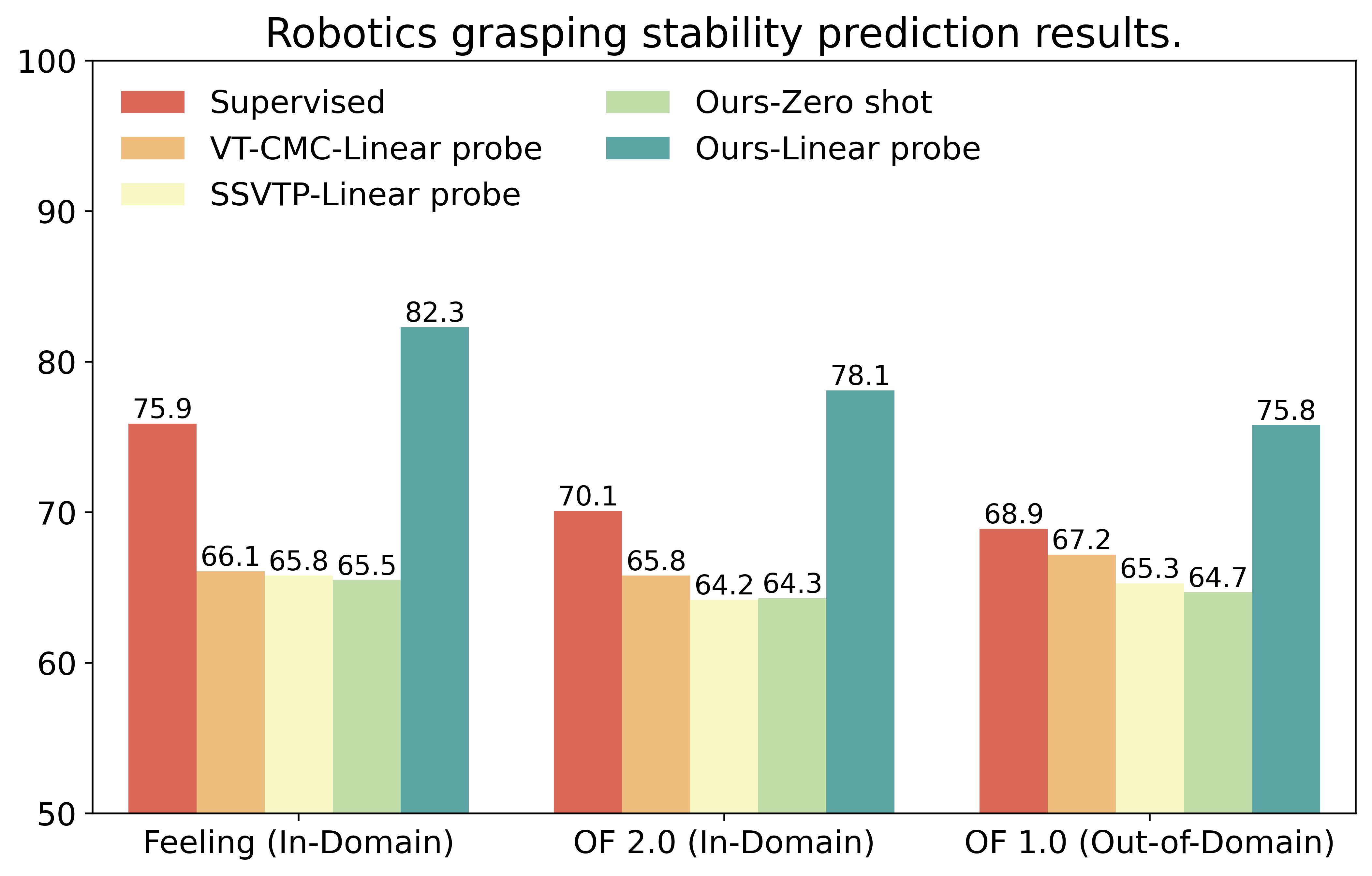
We combine touch with large language models (LLM), allowing us to perform tasks such as tactile question answering in a variety of tactile domains, including contact localization, grasping stability prediction, and etc.

We show images generated solely from touch in a zero-shot manner. We use a pretrained text-to-image diffusion model, conditioned on our touch features.

We show some zero-shot manipulated images by using off-the-shelf text-to-image diffusion model and touch signal.

@article{yang2024unitouch,
title={Binding Touch to Everything: Learning Unified Multimodal Tactile Representations},
author={Yang, Fengyu and Feng, Chao and Chen, Ziyang and
Park, Hyoungseob and Wang, Daniel and Dou, Yiming and
Zeng, Ziyao and Chen, Xien and Gangopadhyay, Rit and
Owens, Andrew and Wong, Alex},
journal={arXiv:2401.18084},
year={2024},
}