We show that the GPS tags contained in photo metadata provide a useful control signal for image generation. We train GPS-to-image models and use them for tasks that require a fine-grained understanding of how images vary within a city. In particular, we train a diffusion model to generate images conditioned on both GPS and text. The learned model generates images that capture the distinctive appearance of different neighborhoods, parks, and landmarks. We also extract 3D models from 2D GPS-to-image models through score distillation sampling, using GPS conditioning to constrain the appearance of the reconstruction from each viewpoint. Our evaluations suggest that our GPS-conditioned models successfully learn to generate images that vary based on location, and that GPS conditioning improves estimated 3D structure.
(a) After downloading geotagged photos, we train GPS-to-image diffusion models conditioned on GPS tags and image captions. GPS tags are extracted from the image EXIF metadata, captions are provided by BLIP-3. The obtained GPS-to-image diffusion model can generate images using both conditioning signals (GPS and text) in a compositional manner. (b) We can also extract 3D models from landmark-specific angle-to-image diffusion models using score distillation sampling. ''+'' in the figure means we concatenate GPS embeddings and text embeddings.

(a) GPS-to-image generation (b) GPS-to-3D reconstruction
Our GPS-to-image model can compose text prompts (optional) and GPS coordinates as conditions to generate corresponding images. Here, we show generated results compared with the pretrained text-to-image model (SD-v1.4) with location text prompts on two well-known areas: New York City and Paris.
New York City
bagel
Map View
[...] + GPS tag

Ours
[...] + in MoMA

Text-to-image
bagel
Map View
[...] + GPS tag

Ours
[...] + in Metropolitan Museum of Art

Text-to-image
aerial view in oil painting style
Map View
[...] + GPS tag

Ours
[...] + in Central Park

Text-to-image
tiger
Map View
[...] + GPS tag

Ours
[...] + in Financial District

Text-to-image
superman
Map View
[...] + GPS tag

Ours
[...] + in Metropolitan Museum of Art

Text-to-image
superman
Map View
[...] + GPS tag

Ours
[...] + in Time Square

Text-to-image
superman
Map View
[...] + GPS tag

Ours
[...] + in Metropolitan Museum of Art

Text-to-image
apple event
Map View
[...] + GPS tag

Ours
[...] + in Madison Square Garden

Text-to-image
street view in acrylic painting style
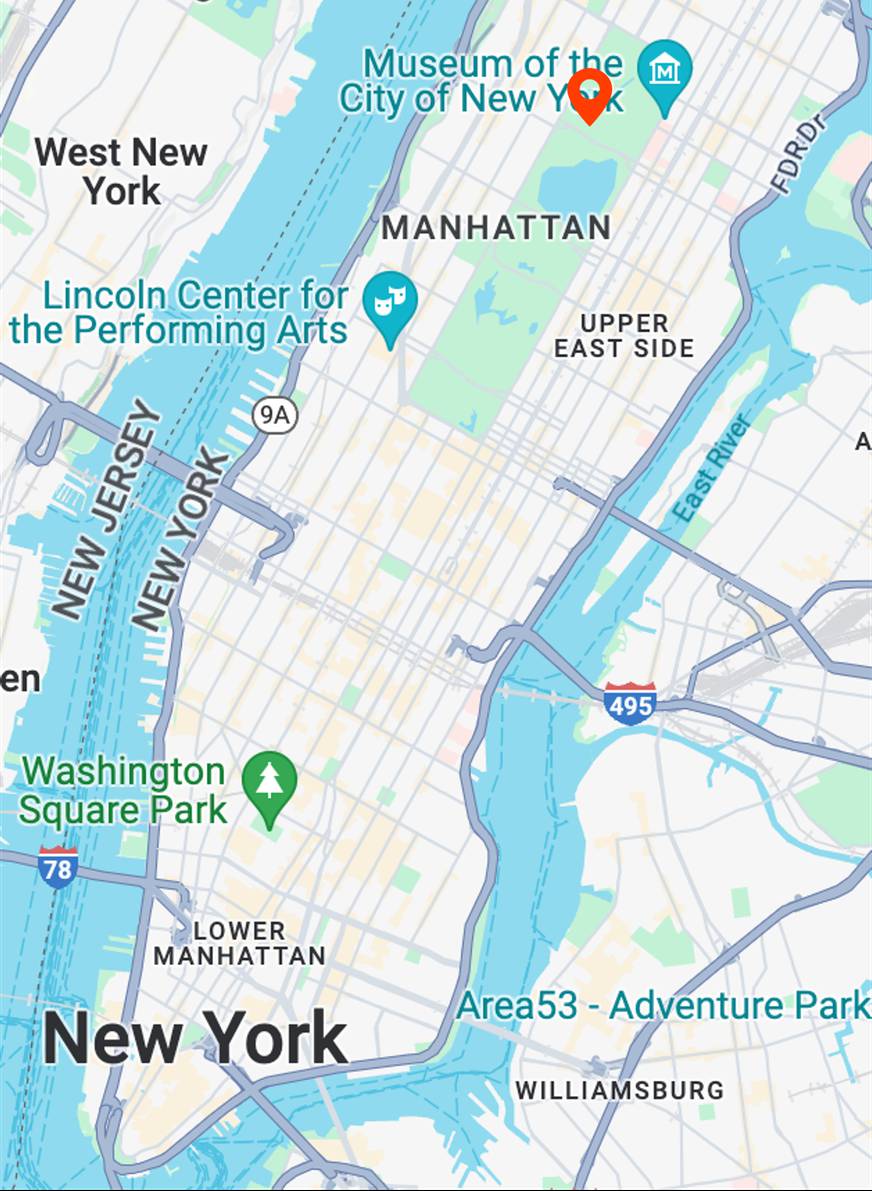
Map View
[...] + GPS tag

Ours
[...] + in Central Park

Text-to-image
tourist bus
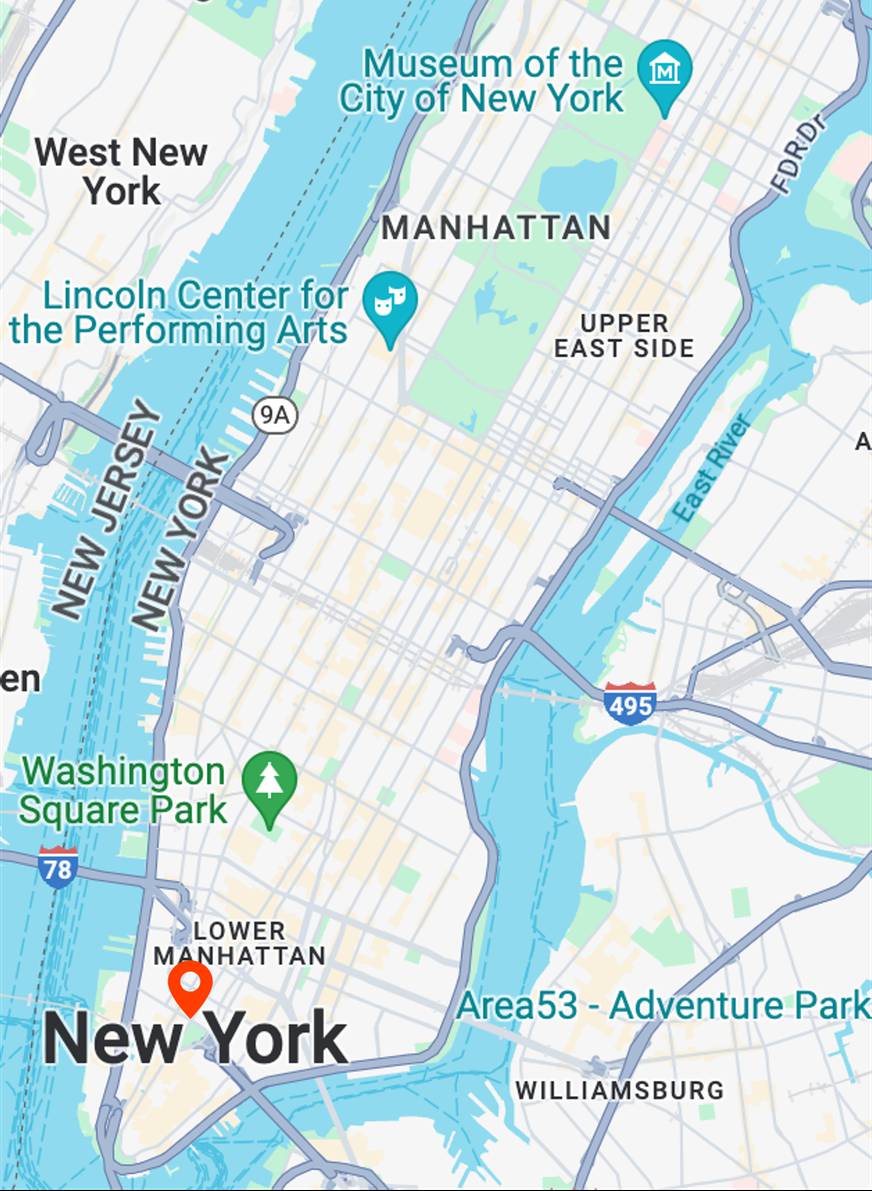
Map View
[...] + GPS tag

Ours
[...] + in Lower Manhattan

Text-to-image
street view in watercolor painting style
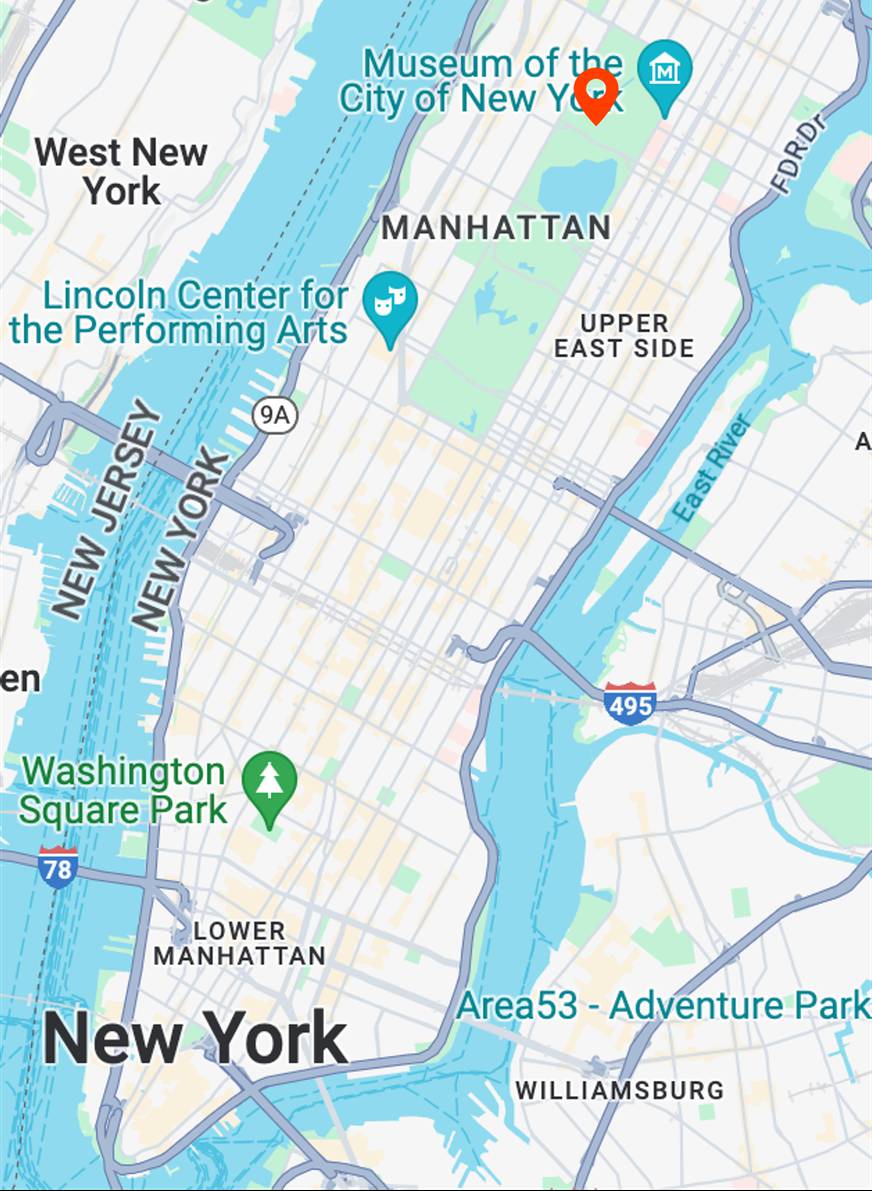
Map View
[...] + GPS tag

Ours
[...] + in Central Park

Text-to-image
street view in oil painting style
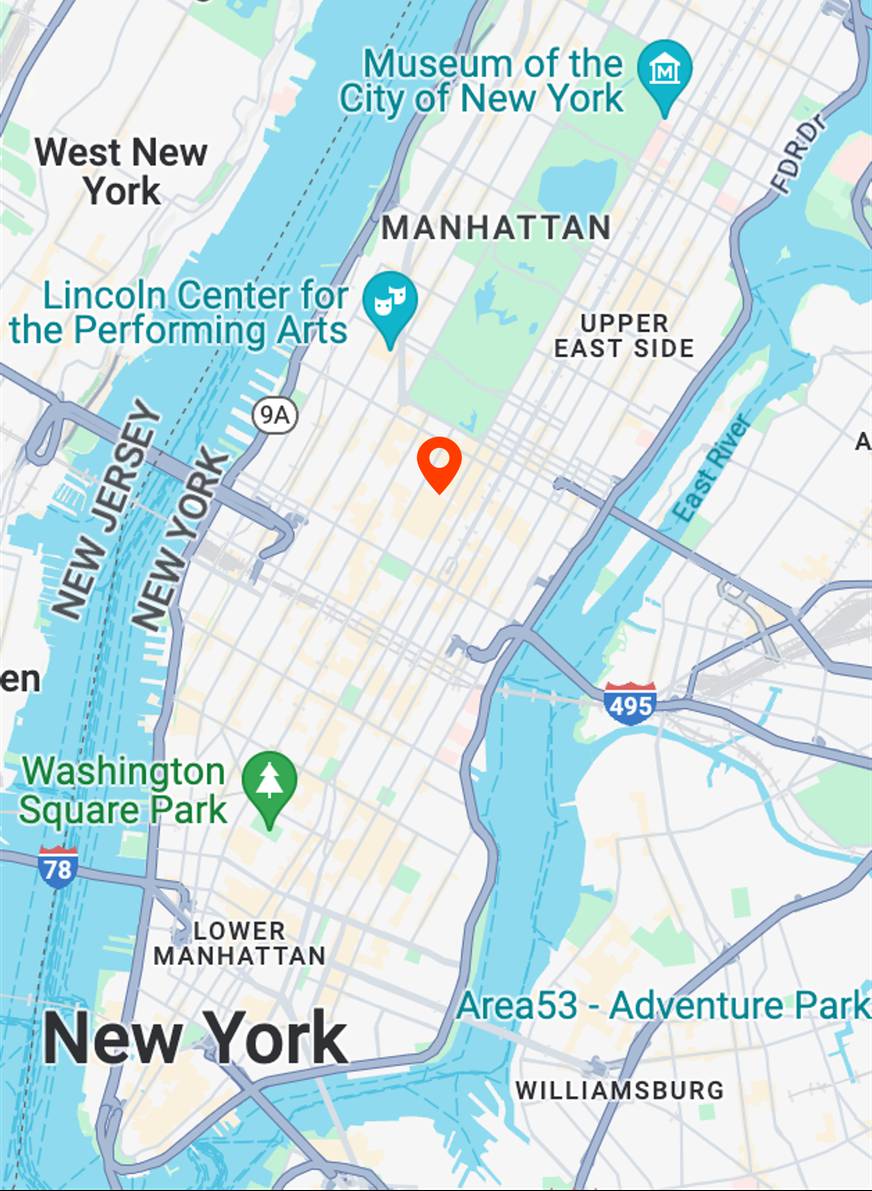
Map View
[...] + GPS tag

Ours
[...] + in Manhattan Midtown

Text-to-image
spring
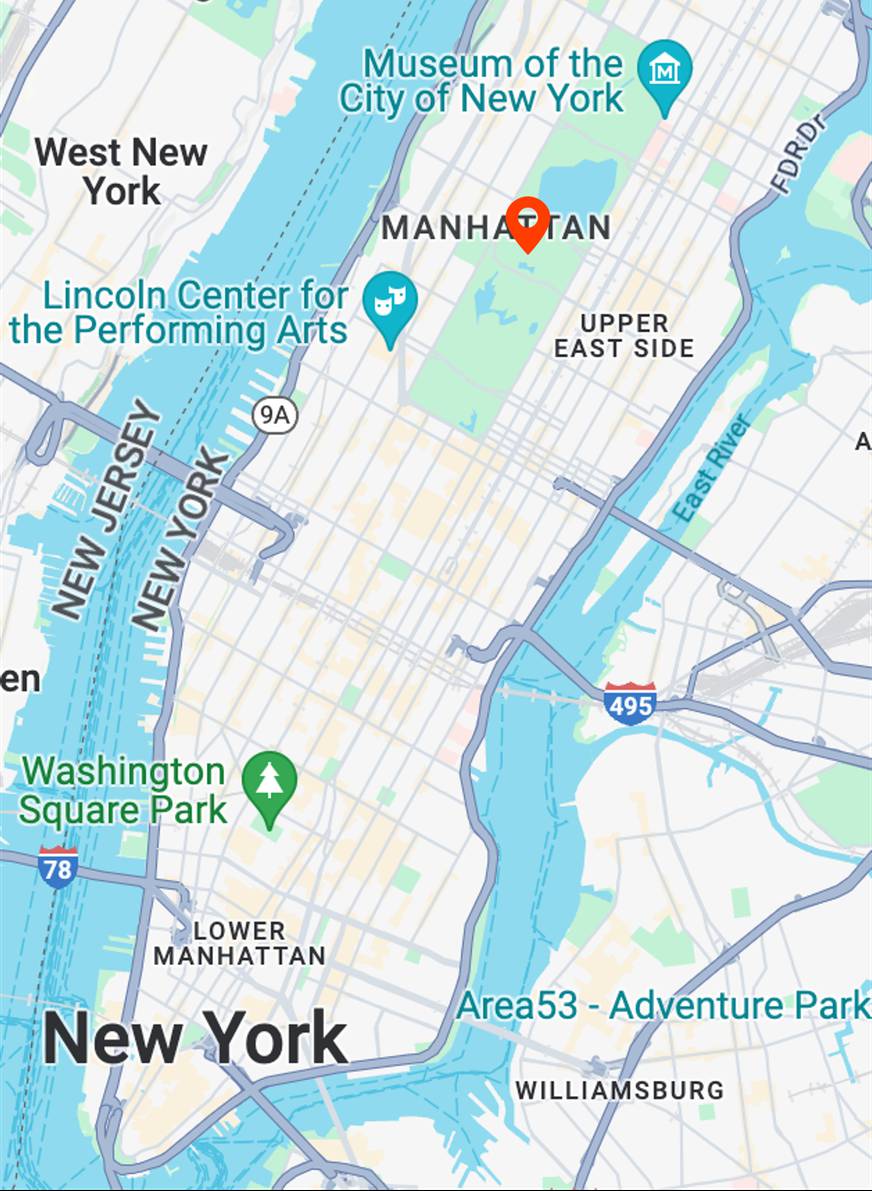
Map View
[...] + GPS tag

Ours
[...] + in Central Park

Text-to-image
spiderman
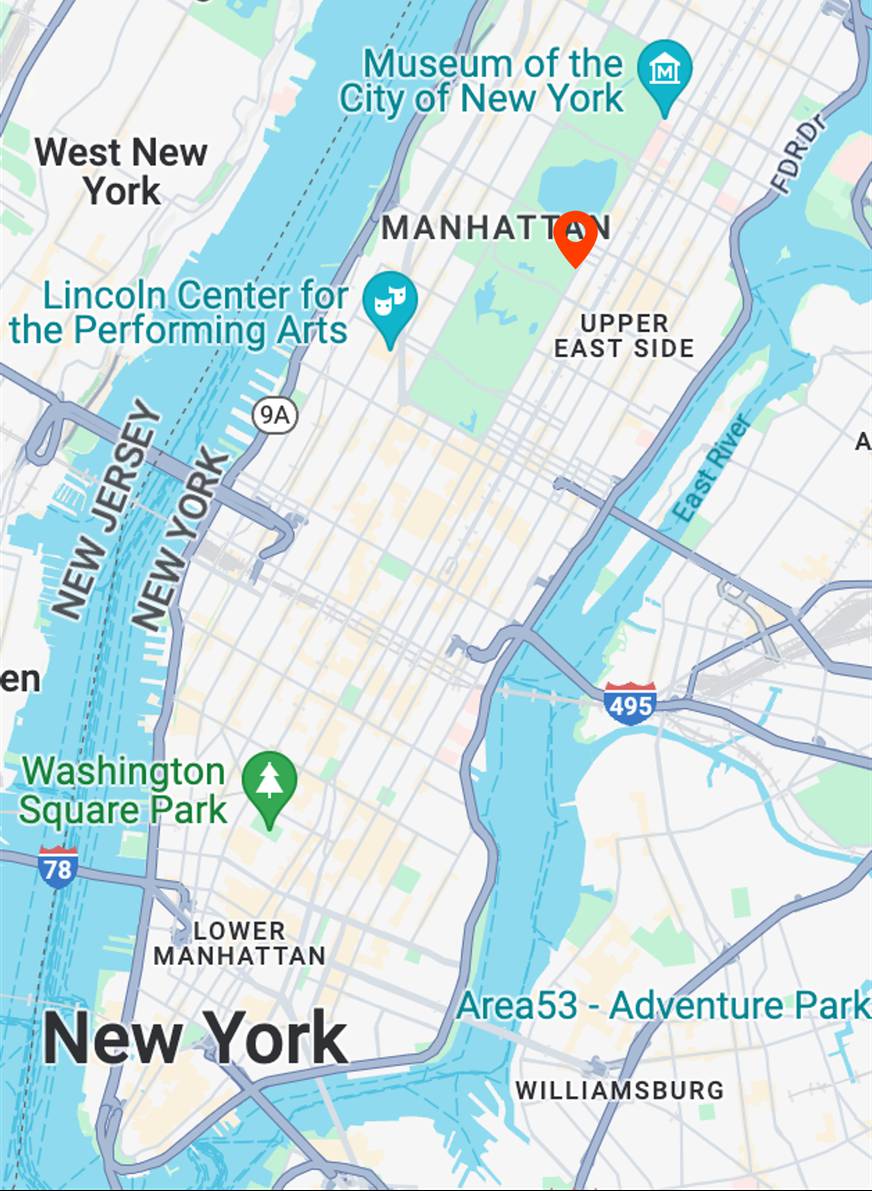
Map View
[...] + GPS tag

Ours
[...] + in Metropolitan Museum of Art

Text-to-image
batman
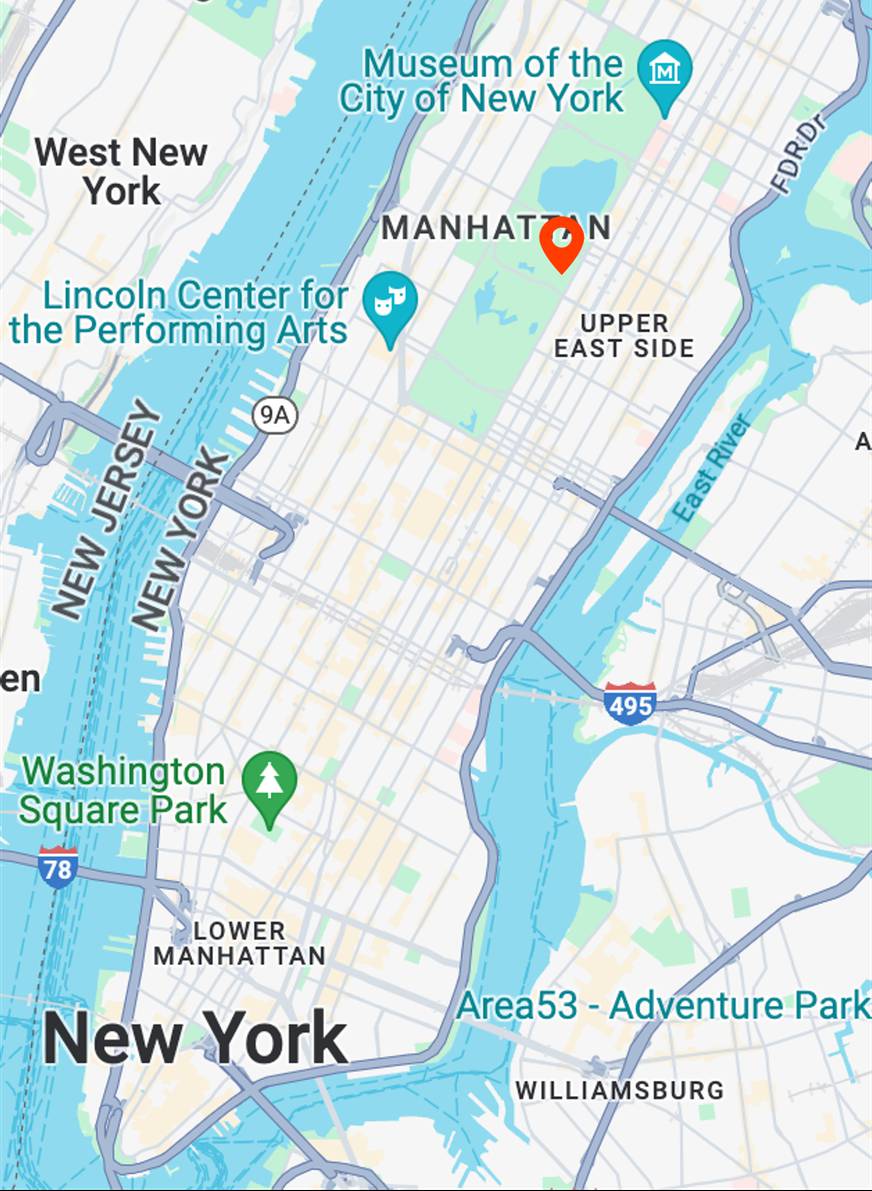
Map View
[...] + GPS tag

Ours
[...] + in Metropolitan Museum of Art

Text-to-image
boat
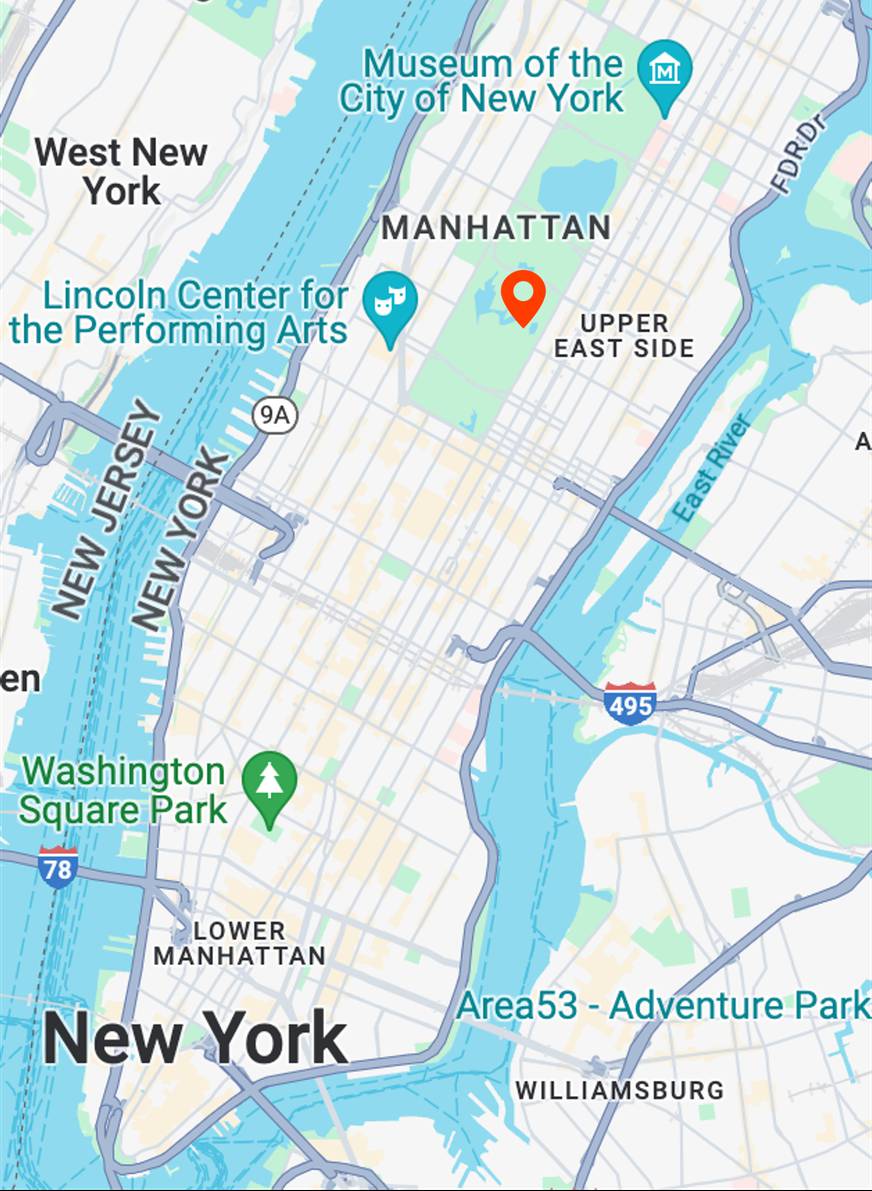
Map View
[...] + GPS tag

Ours
[...] + in Central Park

Text-to-image
rubber duck
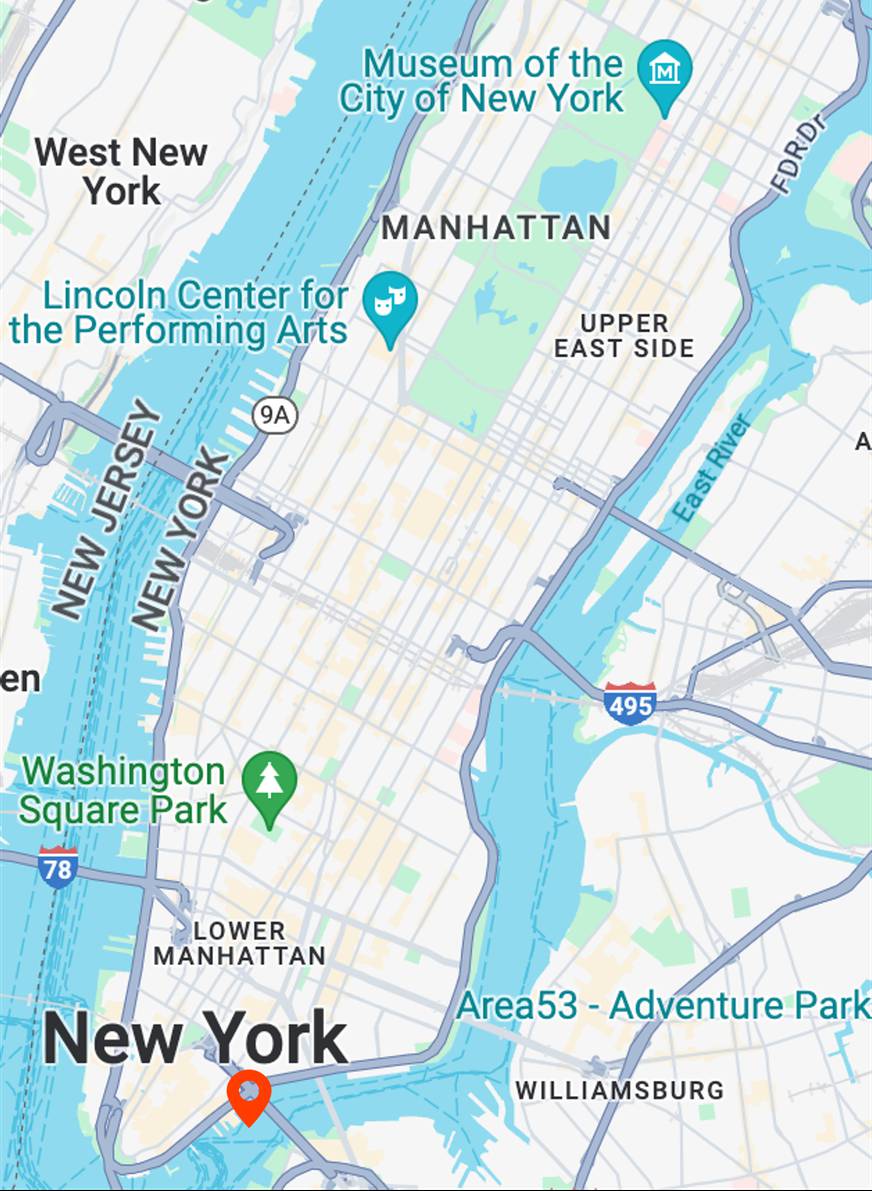
Map View
[...] + GPS tag

Ours
[...] + in The Seaport of New York City

Text-to-image
yellow cab
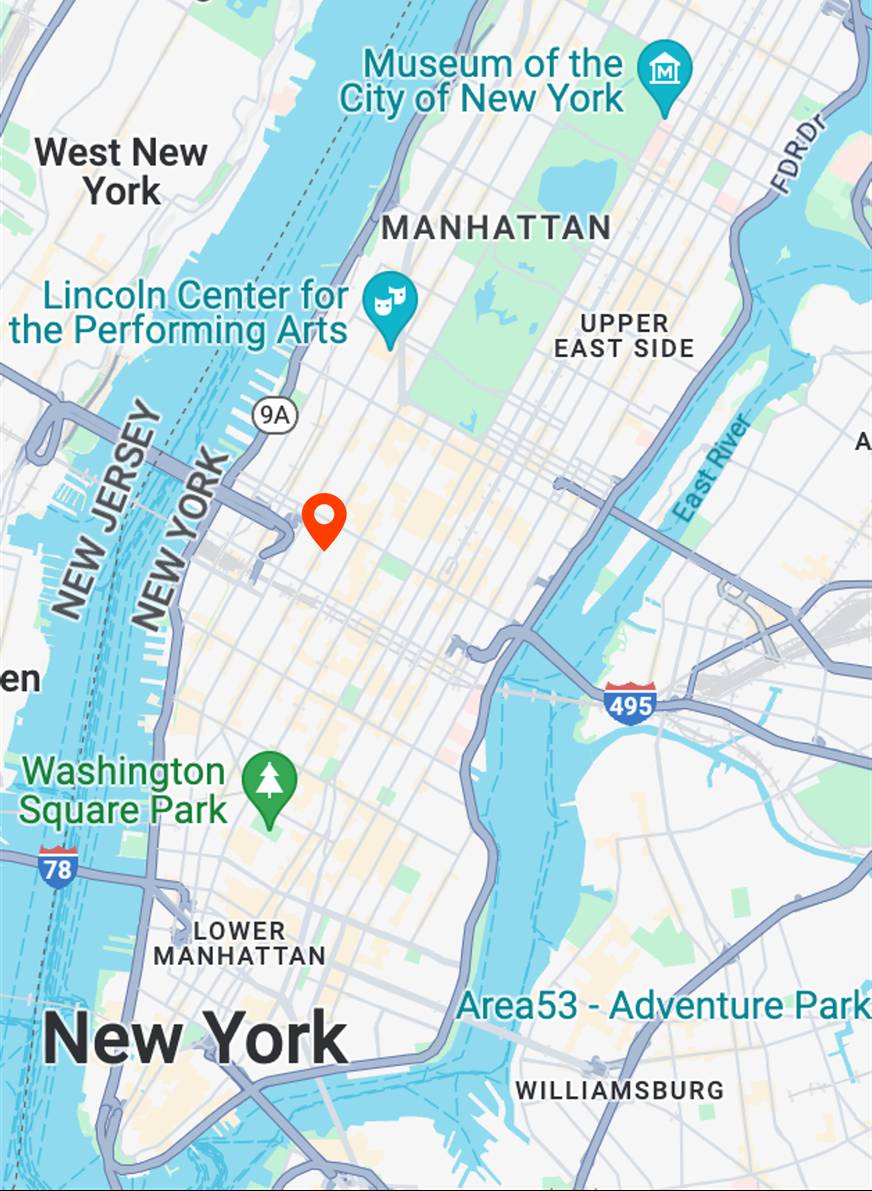
Map View
[...] + GPS tag

Ours
[...] + in Manhattan Midtown

Text-to-image
sunshine
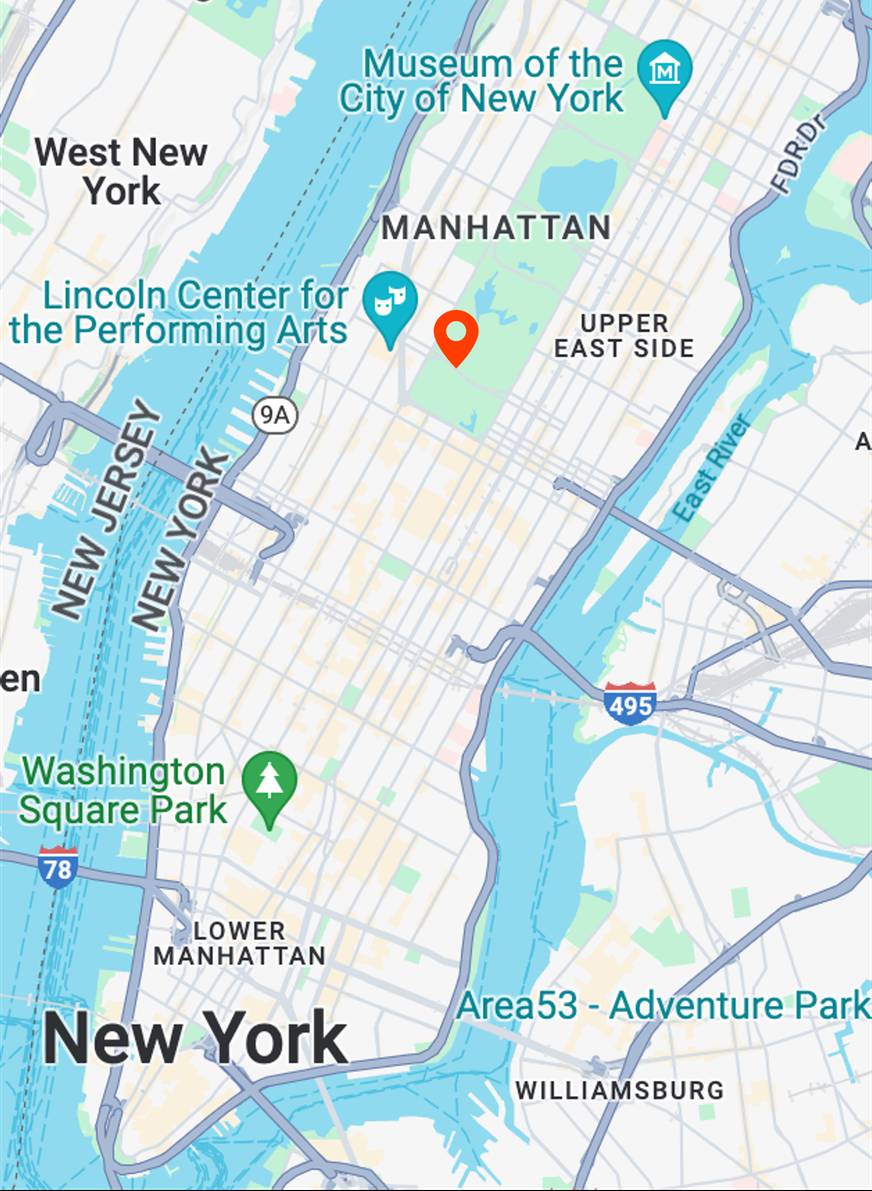
Map View
[...] + GPS tag

Ours
[...] + in Central Park

Text-to-image
selfie
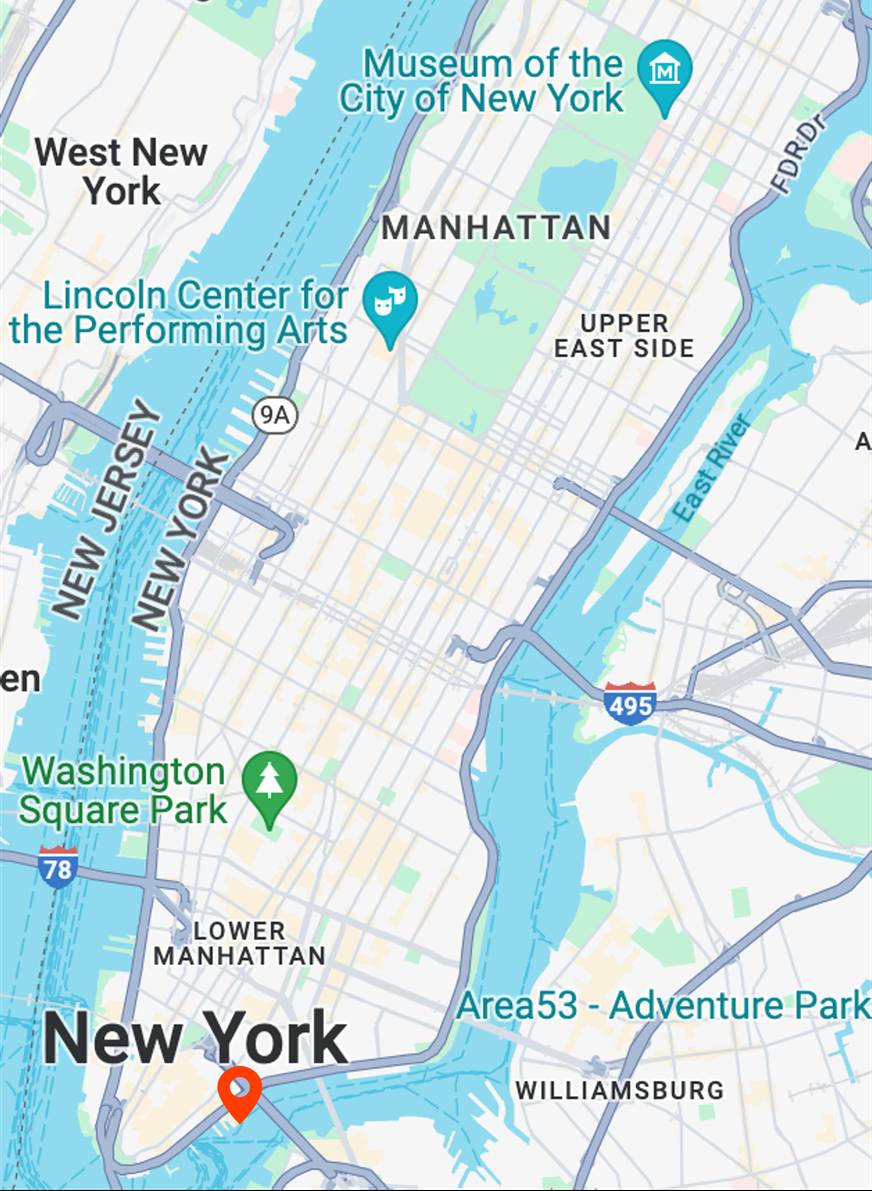
Map View
[...] + GPS tag

Ours
[...] + in The Seaport of New York City

Text-to-image
aerial view
Map View
[...] + GPS tag

Ours
[...] + in Central Park

Text-to-image
tourists
Map View
[...] + GPS tag

Ours
[...] + in Washington Square Park

Text-to-image
selfie
Map View
[...] + GPS tag

Ours
[...] + in Central Park

Text-to-image
selfie
Map View
[...] + GPS tag

Ours
[...] + in Manhattan Midtown

Text-to-image
snowing
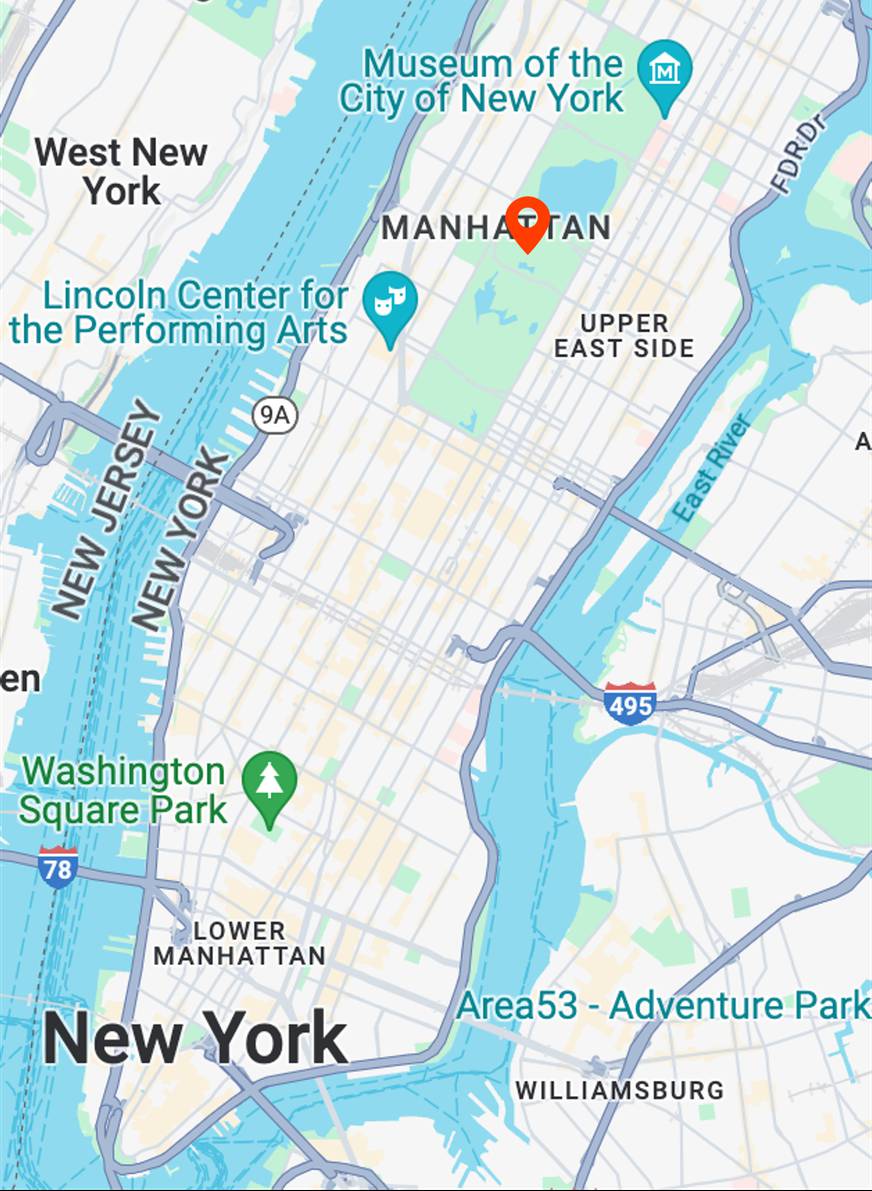
Map View
[...] + GPS tag

Ours
[...] + in Central Park

Text-to-image
autumn
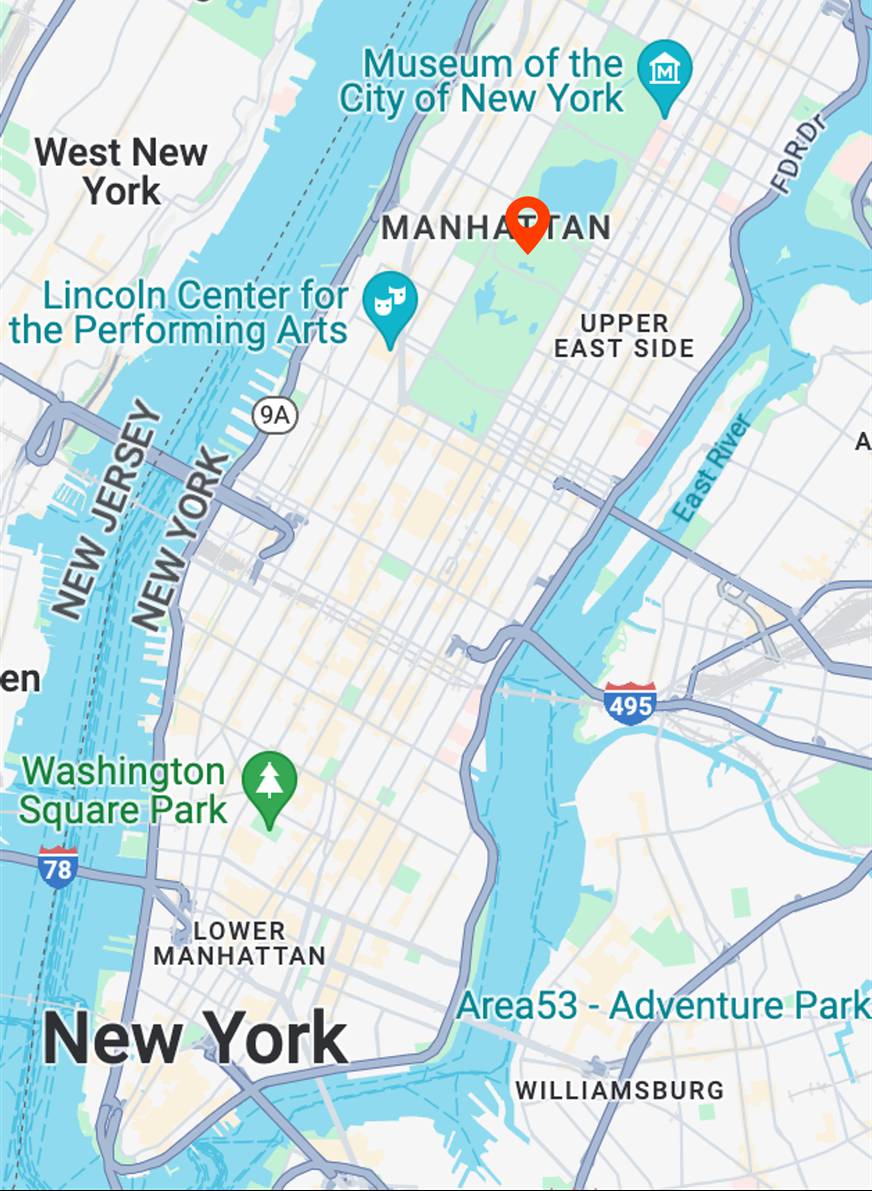
Map View
[...] + GPS tag

Ours
[...] + in Central Park

Text-to-image
pedestrian
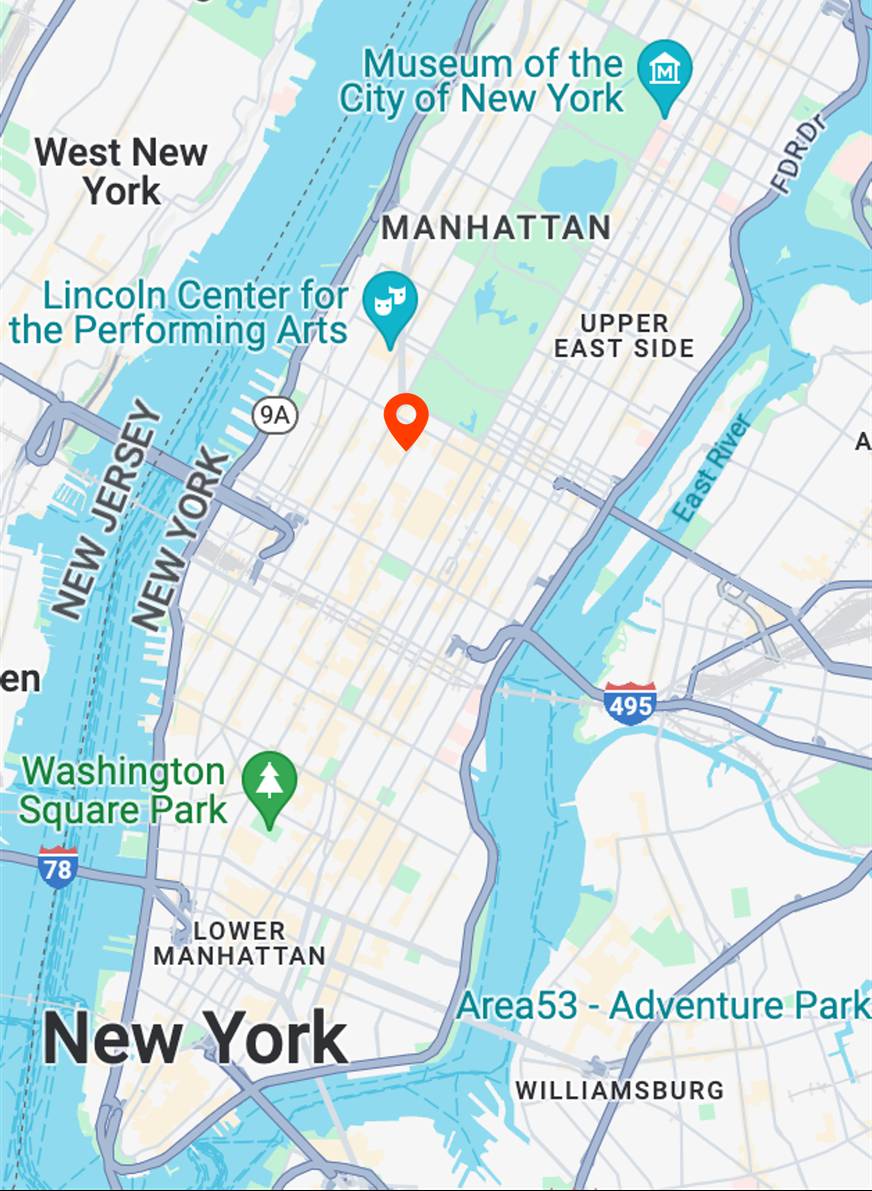
Map View
[...] + GPS tag

Ours
[...] + in Manhattan Midtown

Text-to-image
aerial view
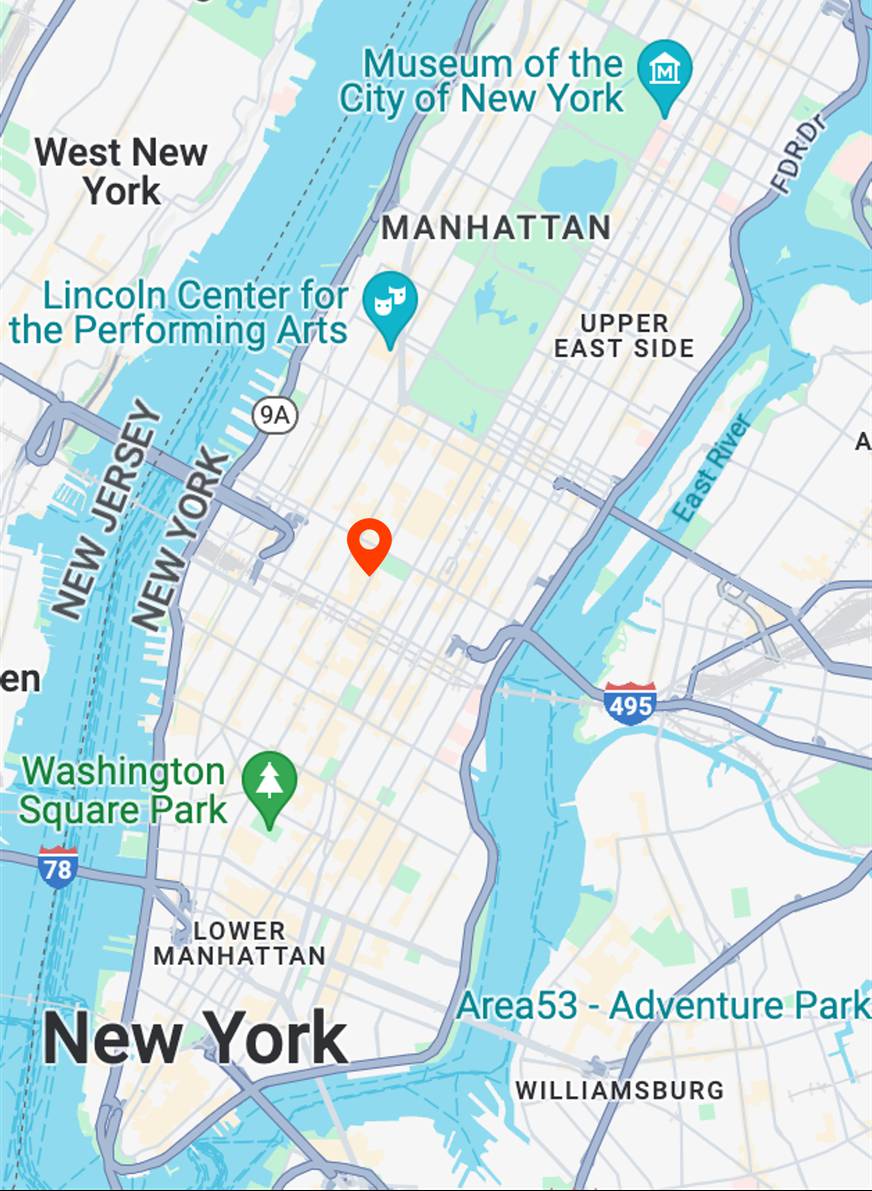
Map View
[...] + GPS tag

Ours
[...] + in Manhattan Midtown

Text-to-image
Paris
batman
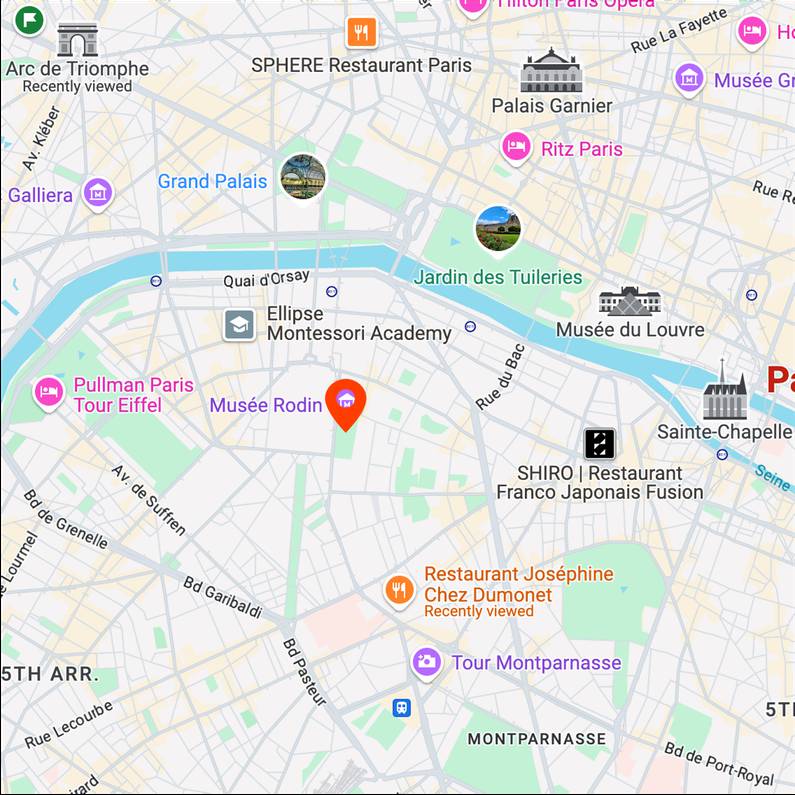
Map View
[...] + GPS tag

Ours
[...] + in Rodin Museum

Text-to-image
spiderman

Map View
[...] + GPS tag

Ours
[...] + in Rodin Museum

Text-to-image
street view in oil painting style
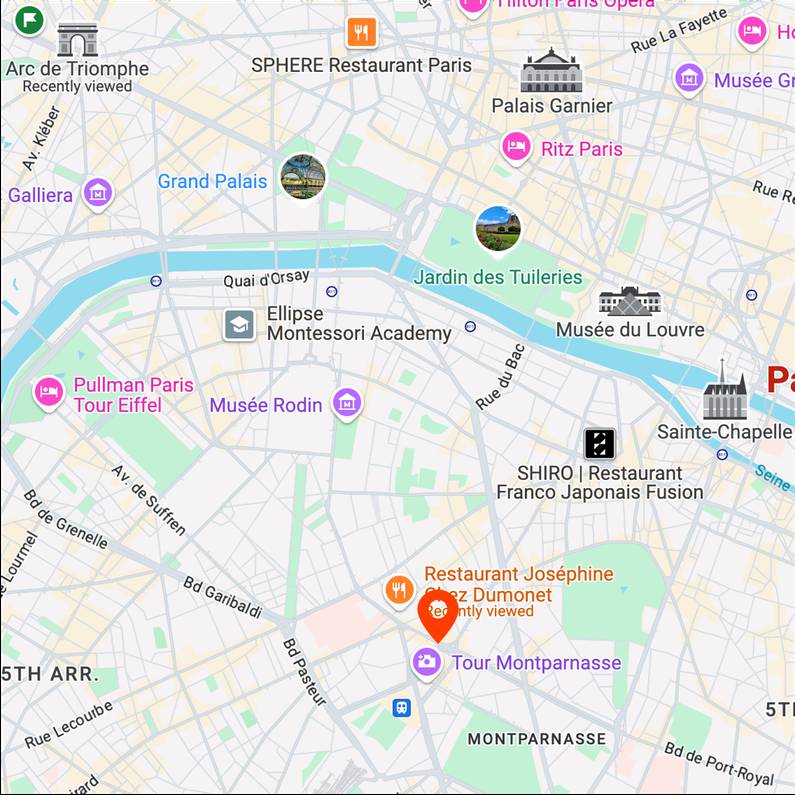
Map View
[...] + GPS tag

Ours
[...] + in 6th arrondissement

Text-to-image
a cup of coffee
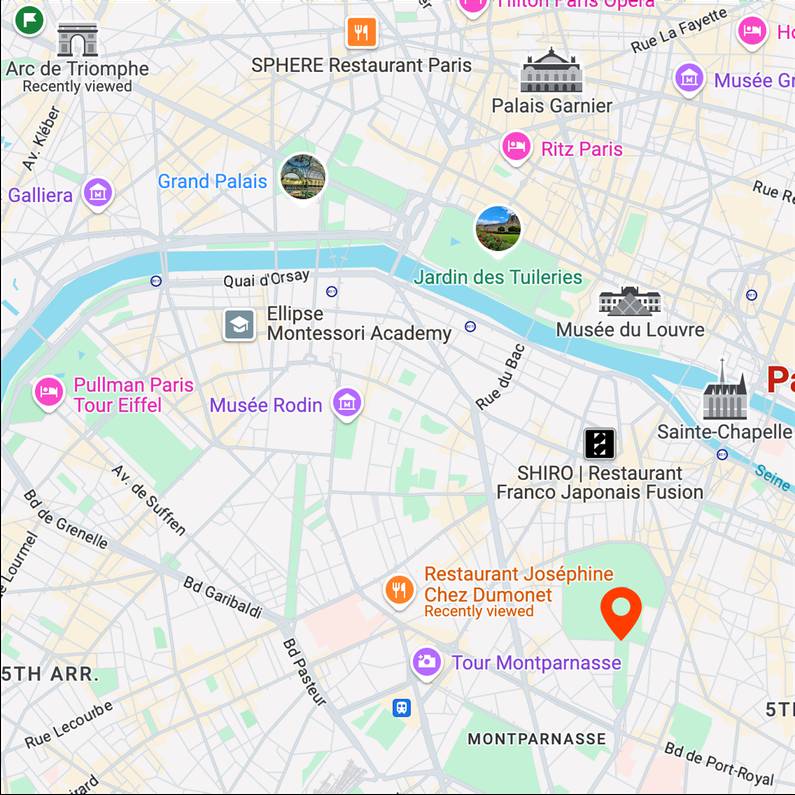
Map View
[...] + GPS tag

Ours
[...] + in Luxembourg Garden

Text-to-image
computer scientist

Map View
[...] + GPS tag

Ours
[...] + in Orsay Museum

Text-to-image
Ben Affleck
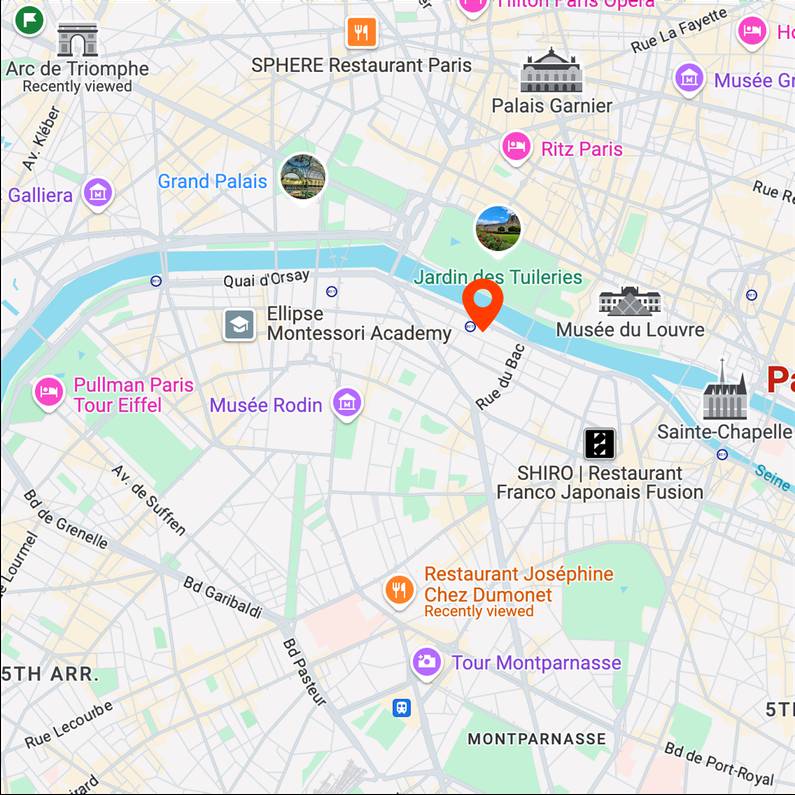
Map View
[...] + GPS tag

Ours
[...] + in Orsay Museum

Text-to-image
tourist
Map View
[...] + GPS tag

Ours
[...] + in Champs-Élysées

Text-to-image
car
Map View
[...] + GPS tag

Ours
[...] + in Champs-Élysées

Text-to-image
batman
Map View
[...] + GPS tag

Ours
[...] + in Louvre Museum

Text-to-image
batman
Map View
[...] + GPS tag

Ours
[...] + in Louvre Museum

Text-to-image
breakfast
Map View
[...] + GPS tag

Ours
[...] + in Orsay Museum

Text-to-image
seine
Map View
[...] + GPS tag

Ours
[...] + in Louvre Museum

Text-to-image
boat
Map View
[...] + GPS tag

Ours
[...] + in Seine

Text-to-image
cloudy
Map View
[...] + GPS tag

Ours
[...] + in Les Invalides

Text-to-image
selfie
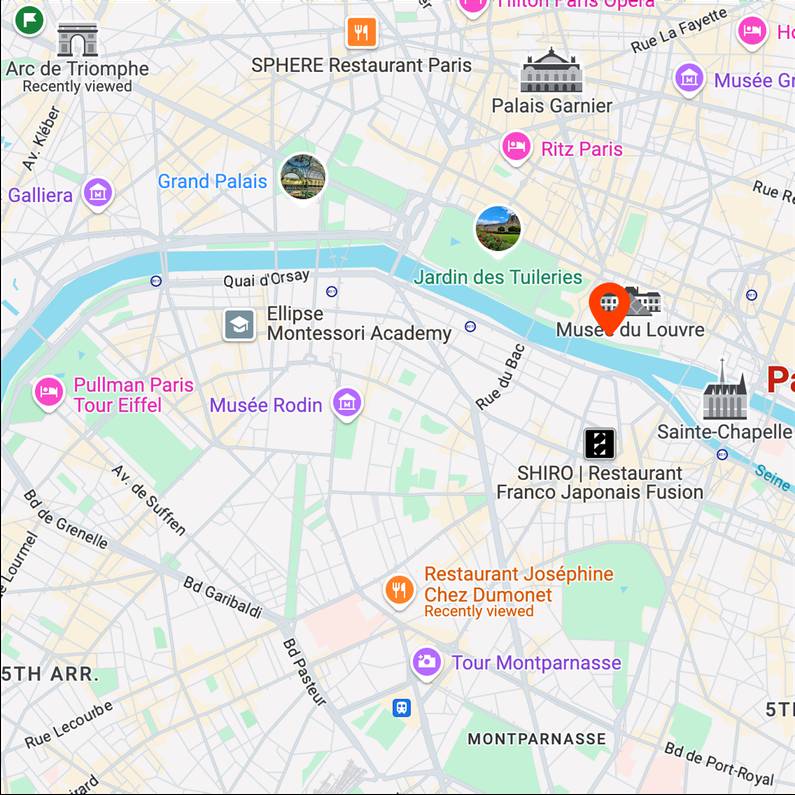
Map View
[...] + GPS tag

Ours
[...] + in Louvre Museum

Text-to-image
vintage car
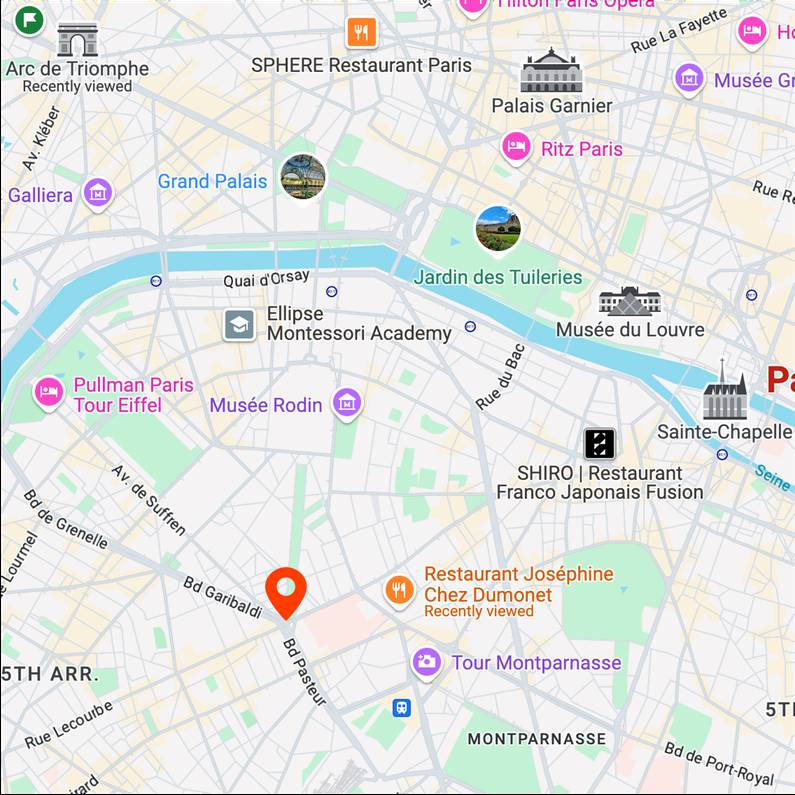
Map View
[...] + GPS tag

Ours
[...] + in 15th arrondissement

Text-to-image
afternoon tea
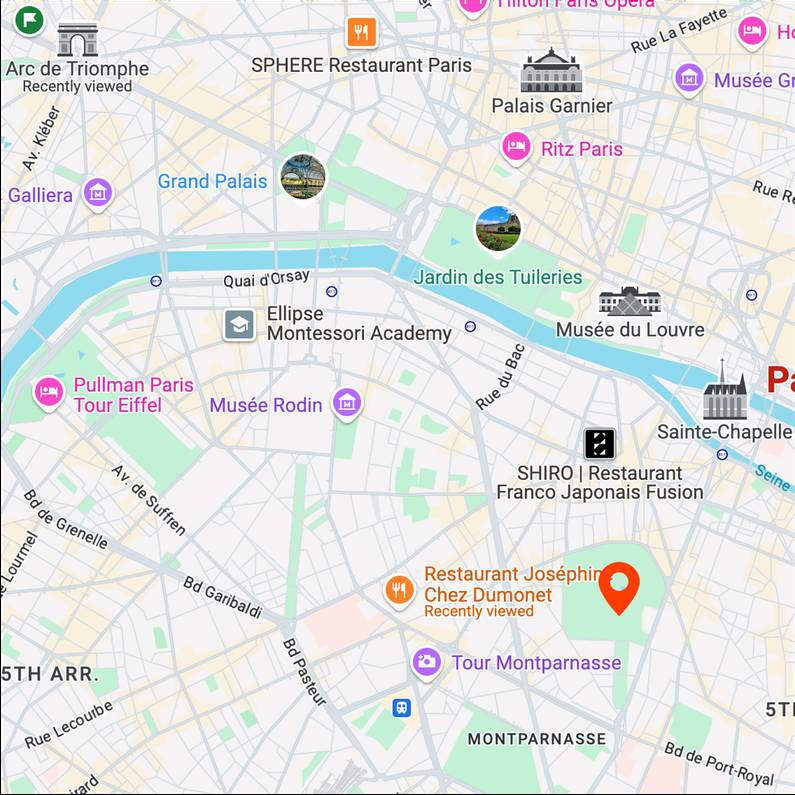
Map View
[...] + GPS tag

Ours
[...] + in Luxembourg Garden

Text-to-image
selfie
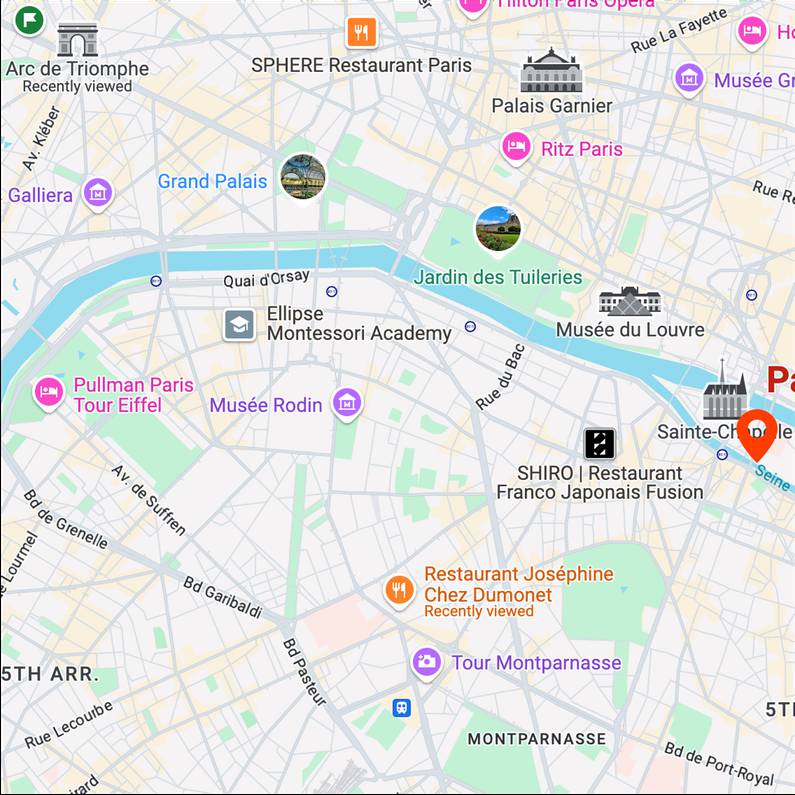
Map View
[...] + GPS tag

Ours
[...] + in Notre Dame Cathedral

Text-to-image
building
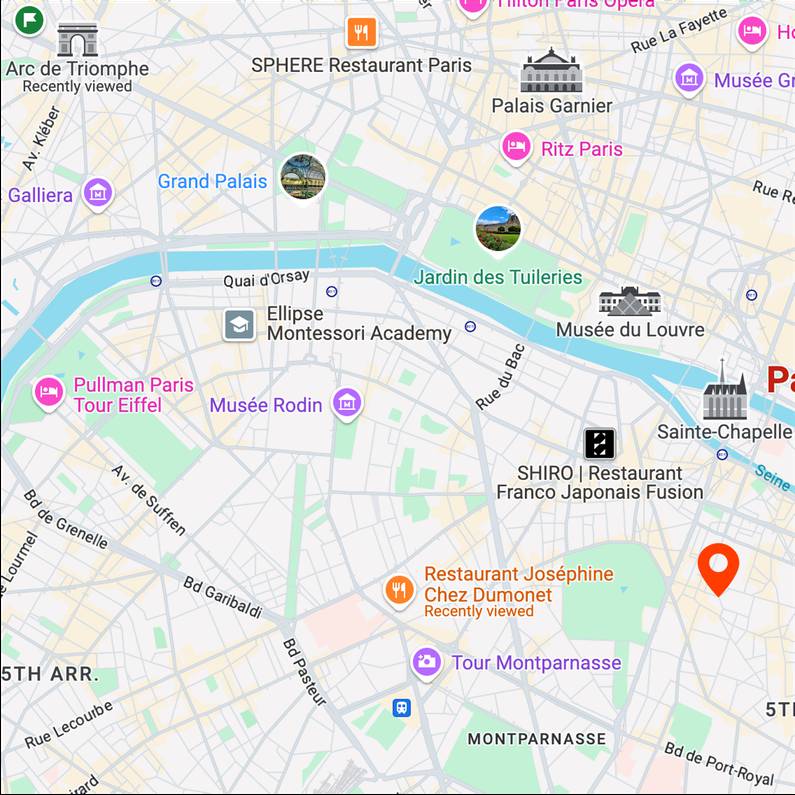
Map View
[...] + GPS tag

Ours
[...] + in Panthéon

Text-to-image
musicals
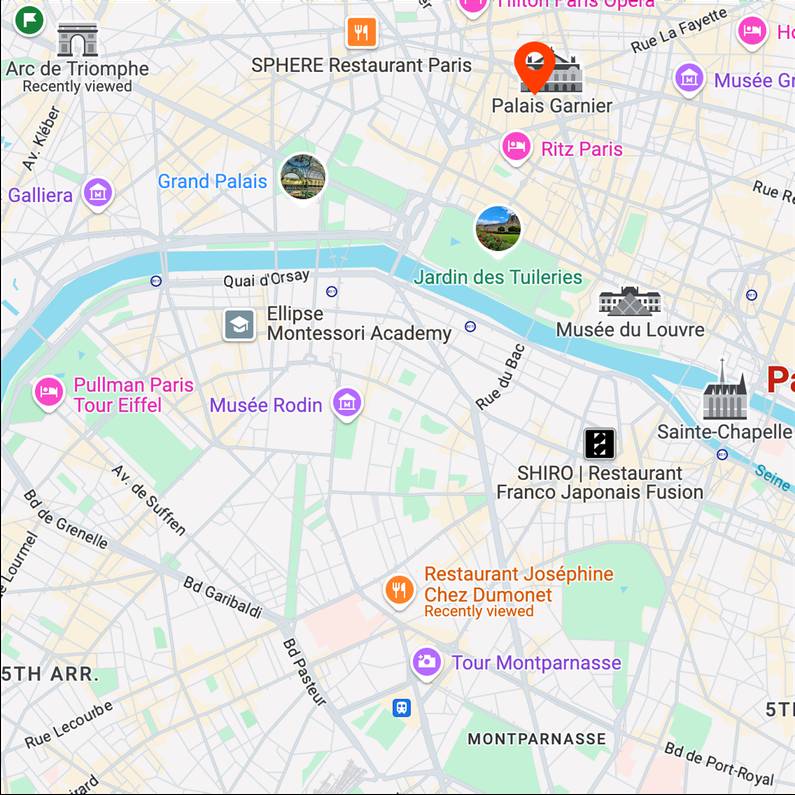
Map View
[...] + GPS tag

Ours
[...] + in Paris Opera

Text-to-image
aerial view
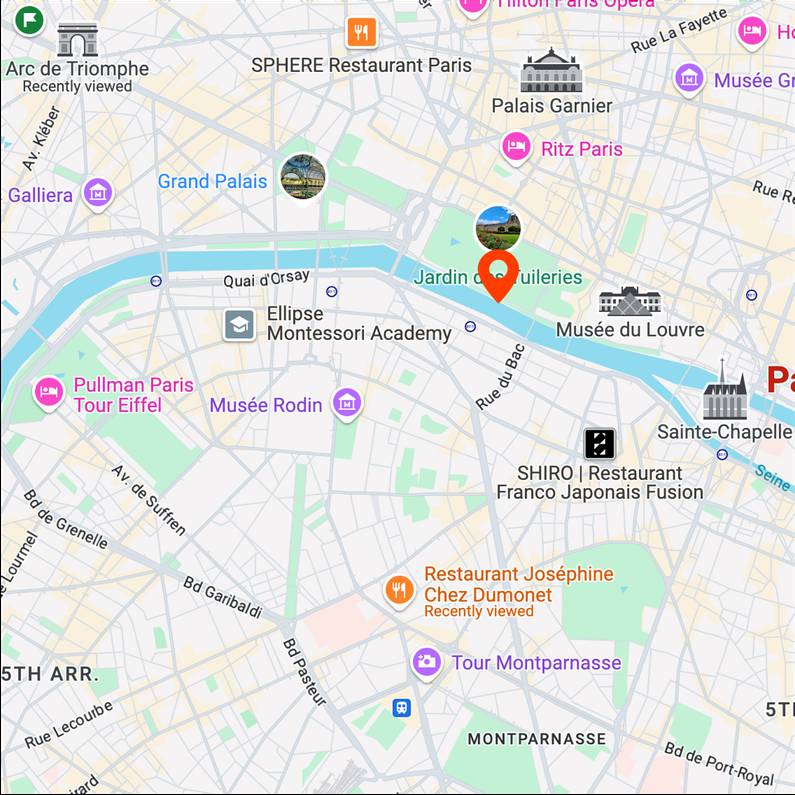
Map View
[...] + GPS tag

Ours
[...] + in Seine

Text-to-image
vintage car
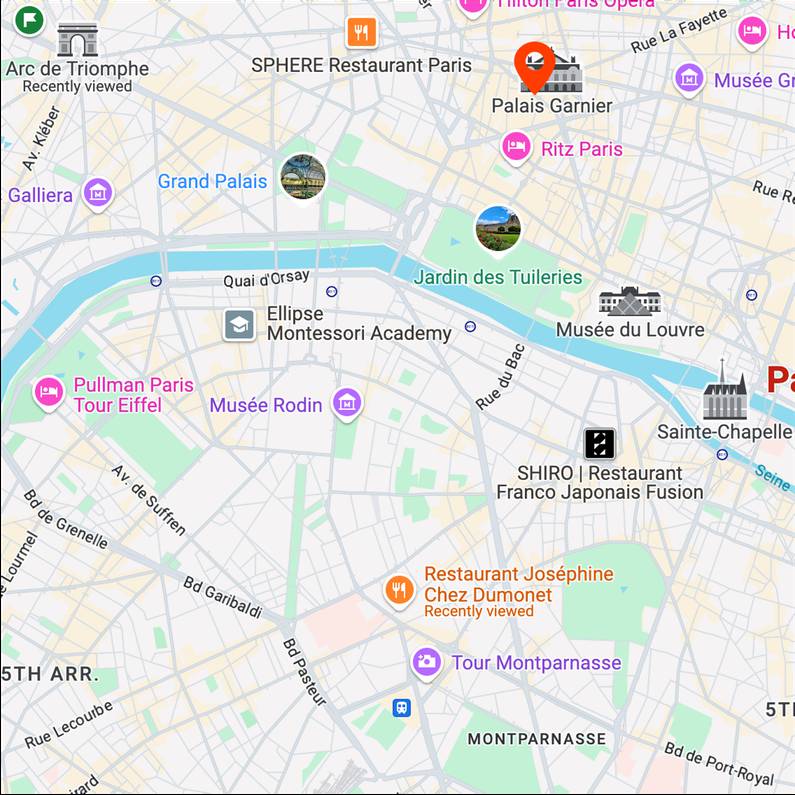
Map View
[...] + GPS tag

Ours
[...] + in Paris Opera

Text-to-image
aerial view
Map View
[...] + GPS tag

Ours
[...] + in Eiffel Tower

Text-to-image
restaurant
Map View
[...] + GPS tag

Ours
[...] + in Quai de Conti

Text-to-image
We apply our GPS-to-image models to the problem of obtaining images that are representative of a given concept over a large geographic area. Specifically, we generate a single image that has high probability under all GPS locations within a user-specified area, as measured by our diffusion model. To do this, following work on compositional generation , we simultaneously estimate noise vectors for a large number of evenly sampled GPS locations and average them during each step of the reverse diffusion process.
building

Average Image
Map View
street view

Average Image
Map View
building

Average Image
Map View
building

Average Image
Map View
building

Average Image
Map View
building

Average Image
Map View
building

Average Image
Map View
building

Average Image
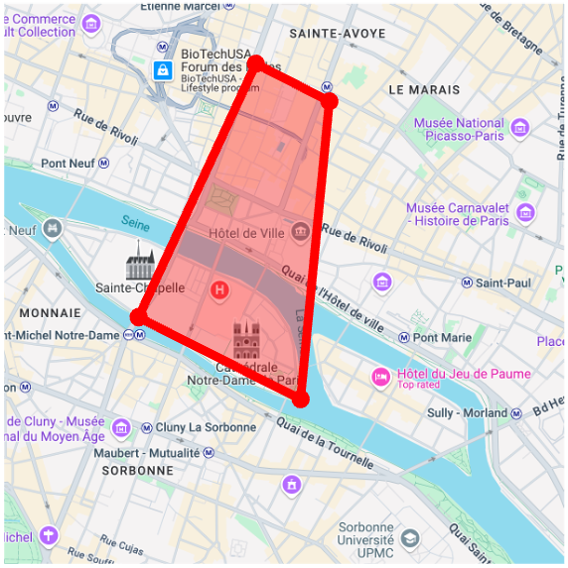
Map View
building

Average Image
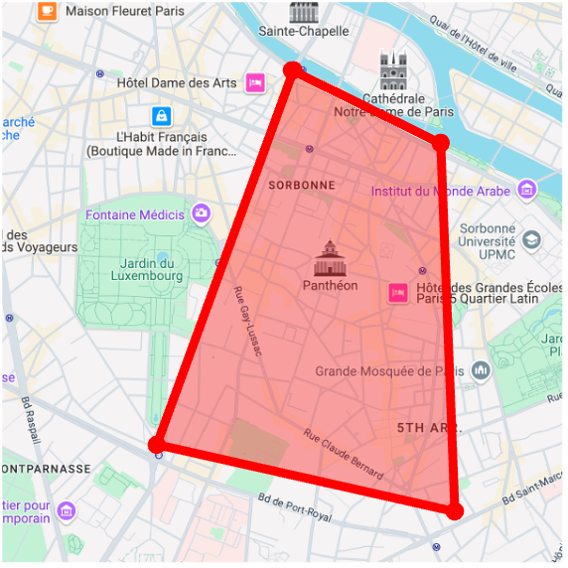
Map View
building

Average Image
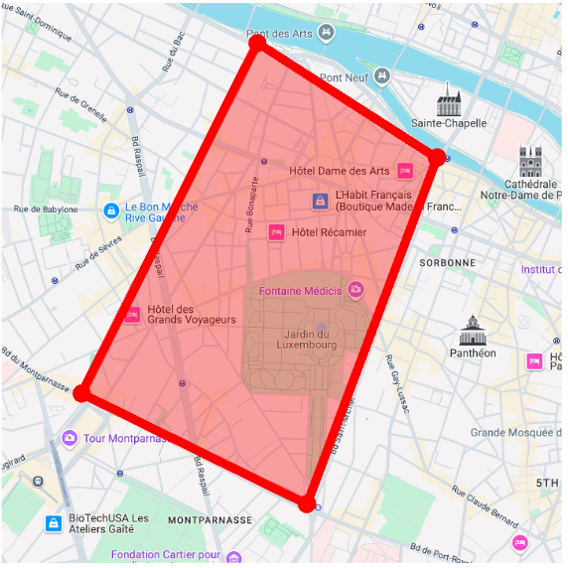
Map View
building

Average Image
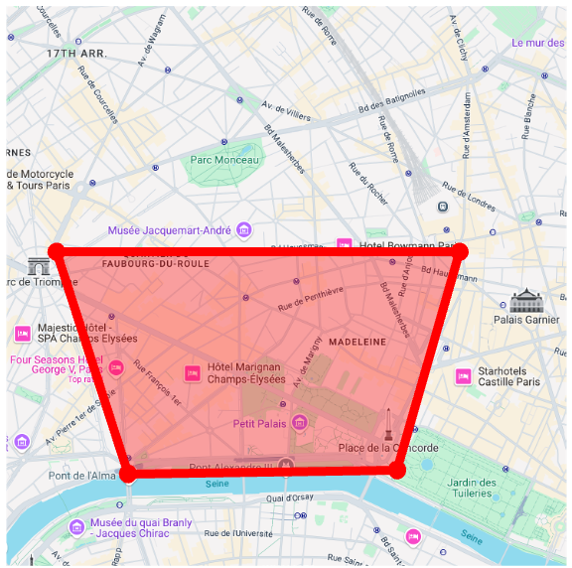
Map View
tree

Average Image
Map View
bricks

Average Image
Map View
building

Average Image
Map View
building

Average Image
Map View
building

Average Image
Map View
building

Average Image
Map View
building

Average Image
Map View
tree

Average Image
Map View
bricks

Average Image
Map View
All images are from the same initial random noise.
Through score distillation sampling from our angle-to-image diffusion models trained on unordered collections of geo-tagged photos, we can obtain better 3D models for scenes compared to models that use only text conditioning.






@article{feng2025gps,
author = {Feng, Chao and Chen, Ziyang and Holynski, Aleksander and Efros, Alexei A and Owens, Andrew},
title = {GPS as a Control Signal for Image Generation},
year = {2025},
}