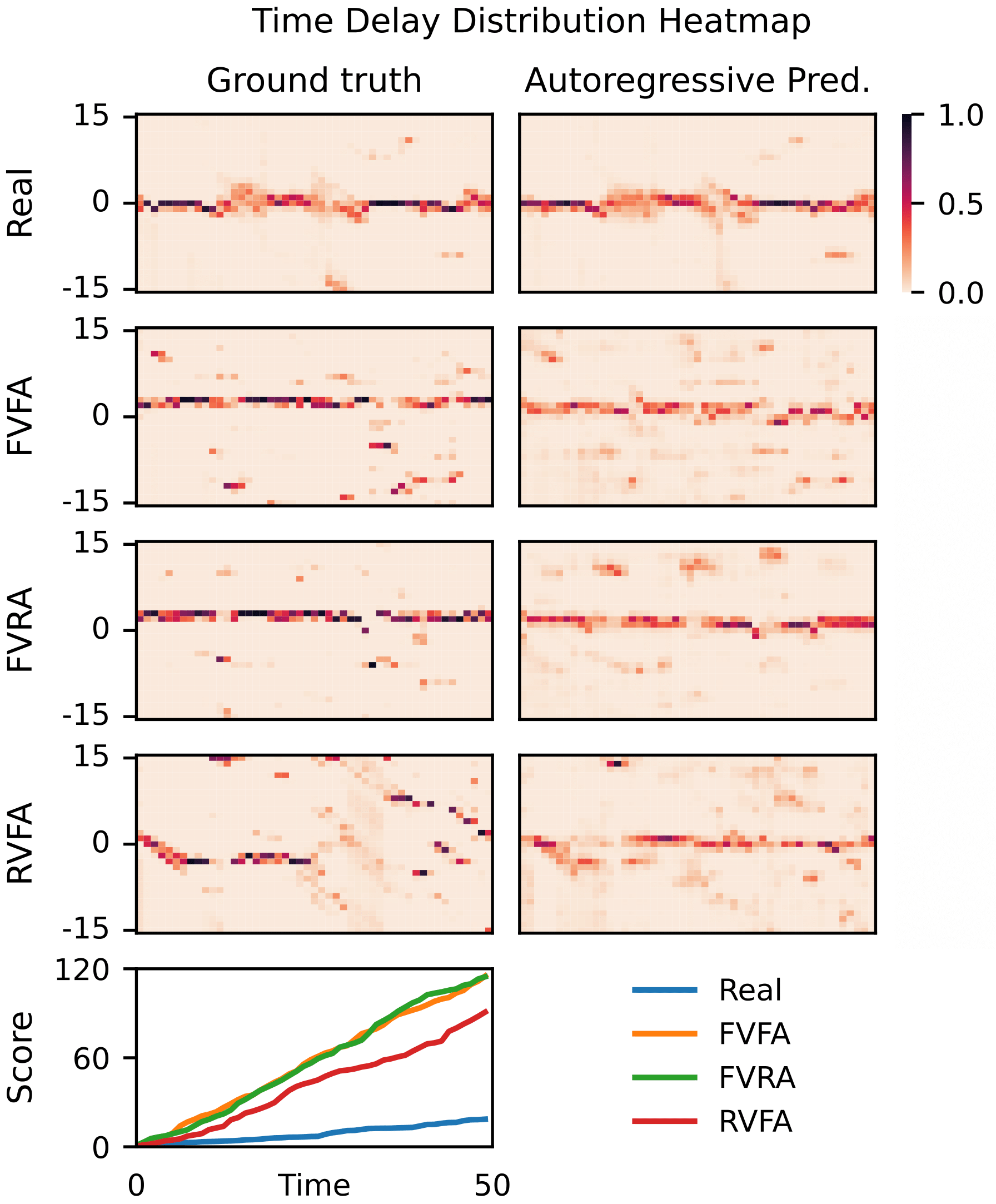
Qualitative Results
Time Delay Visualization
Video Demo
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
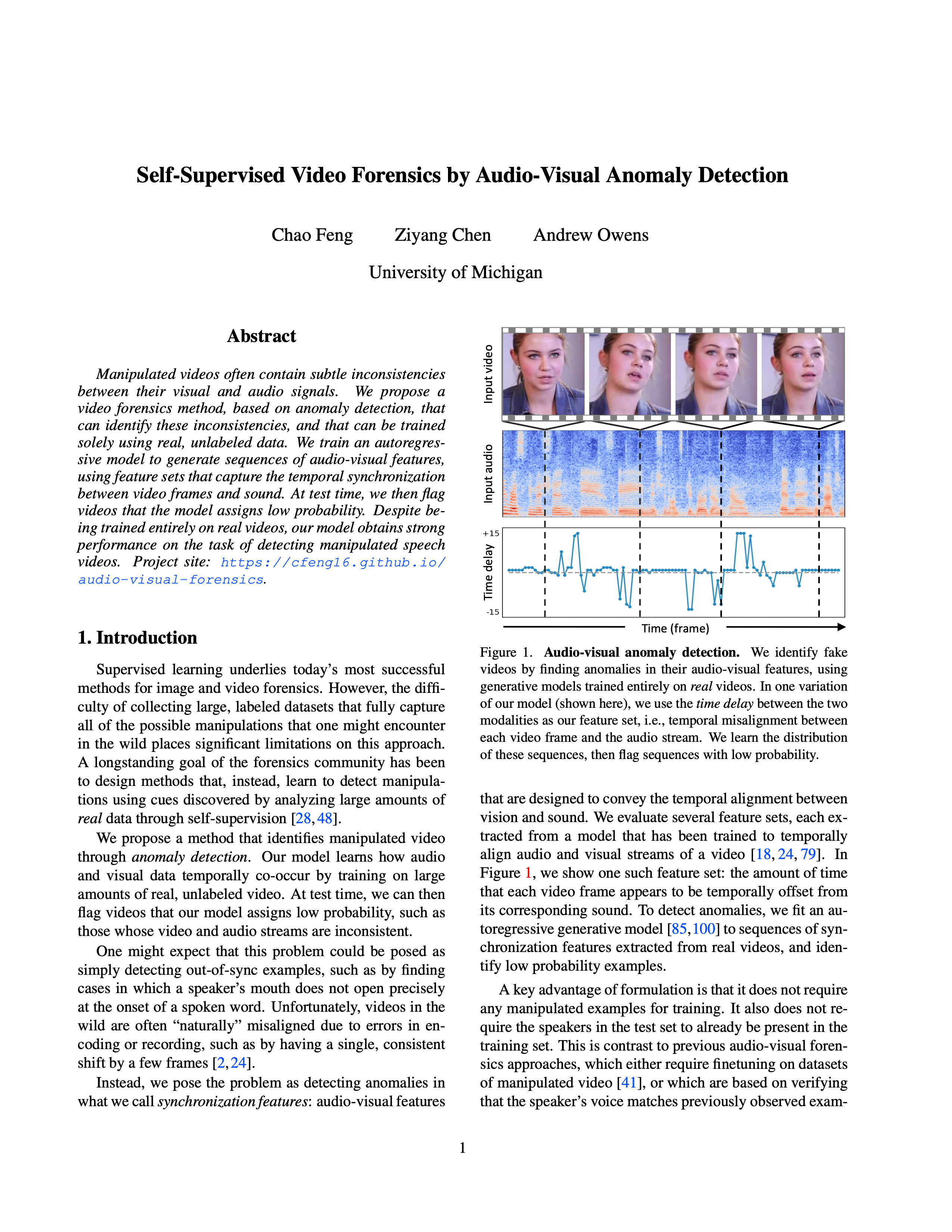
| Manipulated videos often contain subtle inconsistencies between their visual and audio signals. We propose a video forensics method, based on anomaly detection, that can identify these inconsistencies, and that can be trained solely using real, unlabeled data. We train an autoregressive model to generate sequences of audio-visual features, using feature sets that capture the temporal synchronization between video frames and sound. At test time, we then flag videos that the model assigns low probability. Despite being trained entirely on real videos, our model obtains strong performance on the task of detecting manipulated speech videos. |
|
|
Time Delay Visualization |
|
Video Demo |
|
|
|
|
 |
Chao Feng, Ziyang Chen, Andrew Owens. Self-Supervised Video Forensics by Audio-Visual Anomaly Detection. CVPR 2023. (ArXiv) |
Acknowledgements
We thank David Fouhey, Richard Higgins, Sarah Jabbour, Yuexi Du, Mandela Patrick, Deva Ramanan, Haochen Wang, and Aayush Bansal for helpful discussions. This work was supported in part by DARPA Semafor and Cisco Systems. The views, opinions and/or findings expressed are those of the authors and should not be interpreted as representing the official views or policies of the Department of Defense or the U.S. Government. The webpage template was originally made by Phillip Isola and Richard Zhang for a Colorization project.
|
|