|
I am a second-year PhD student in Computer Science at Cornell Tech, Cornell University, working with Andrew Owens. Prior to that, I was a master's student at the University of Michigan (UMich). Feel free to contact me. Email: cf583 at cornell dot edu |

|
|
|
|
|
Adobe Research
Research Scientist Intern Summer, 2025 Topics: Video Diffusion Models, RL Post-training, Unified Generative Models |
|
I'm interested in computer vision, multimodal learning, and generative models. Please see Google Scholar.
|

|
ViCrit: A Verifiable Reinforcement Learning Proxy Task for Visual Perception in VLMs
Xiyao Wang*, Zhengyuan Yang*, Chao Feng*, Yongyuan Liang, Yuhang Zhou, Xiaoyu Liu, Ziyi Zang, Ming Li, Chung-Ching Lin, Kevin Lin, Linjie Li, Furong Huang, Lijuan Wang, NeurIPS, 2025 paper
|
|
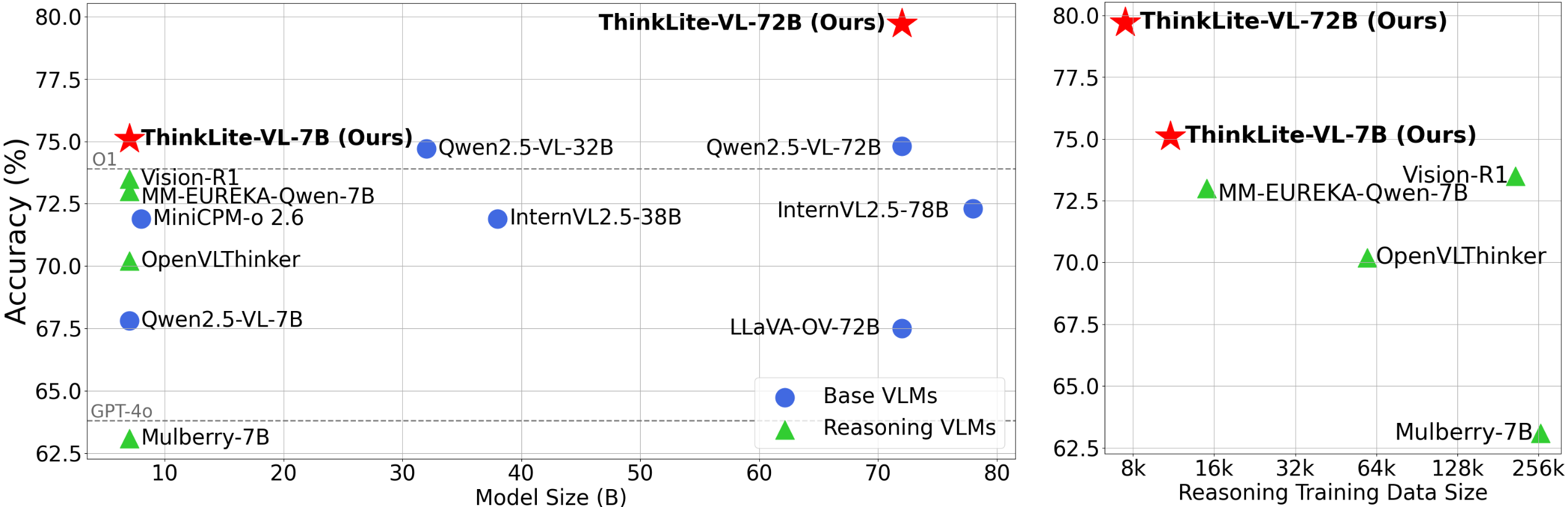
SoTA with Less: MCTS-Guided Sample Selection for Data-Efficient Visual Reasoning Self-Improvement
Xiyao Wang, Zhengyuan Yang, Chao Feng, Hongjin Lu, Linjie Li, Chung-Ching Lin, Kevin Lin, Furong Huang, Lijuan Wang, NeurIPS, 2025 (Spotlight) paper
|
|
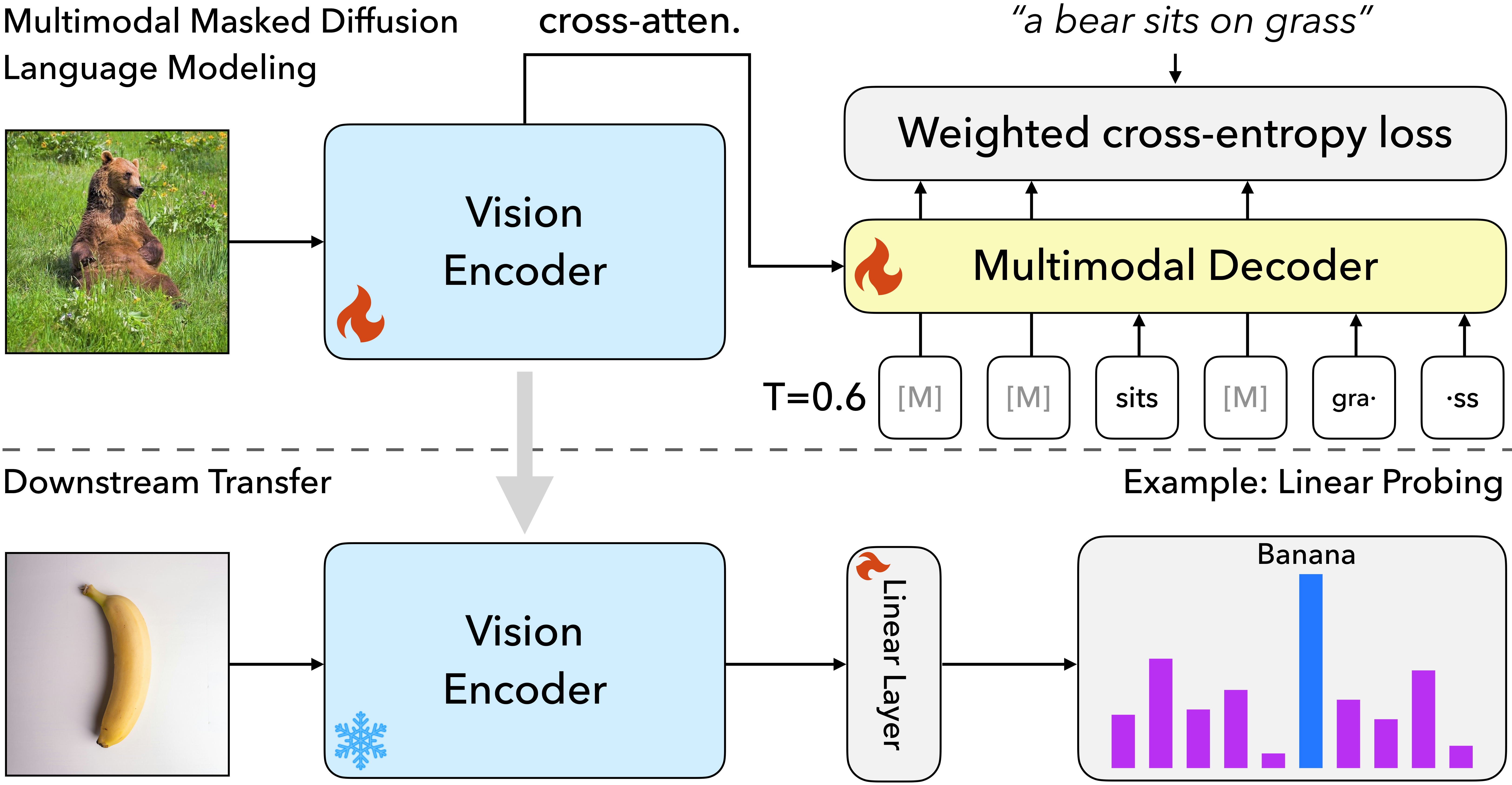
Masked Diffusion Captioning for Visual Feature Learning
Chao Feng, Zihao Wei, Andrew Owens, EMNLP, 2025 (Findings) project page / paper We train image conditioned diffusion language models to learn visual representations.
|
|
GPS as a Control Signal for Image Generation
Chao Feng, Ziyang Chen, Aleksander Holynski, Alexei A. Efros, Andrew Owens, CVPR, 2025 project page / paper We train GPS conditioned diffusion models to sample images.
|

|
This&That: Language-Gesture Controlled Video Generation for Robot Planning
Boyang Wang , Nikhil Sridhar, Chao Feng, Mark Van der Merwe, Adam Fishman, Nima Fazeli, Jeong Joon Park, ICRA, 2025 project page / paper We introduce This&That, a framework that generates videos from text instructions and gestures for robot planning. |
|
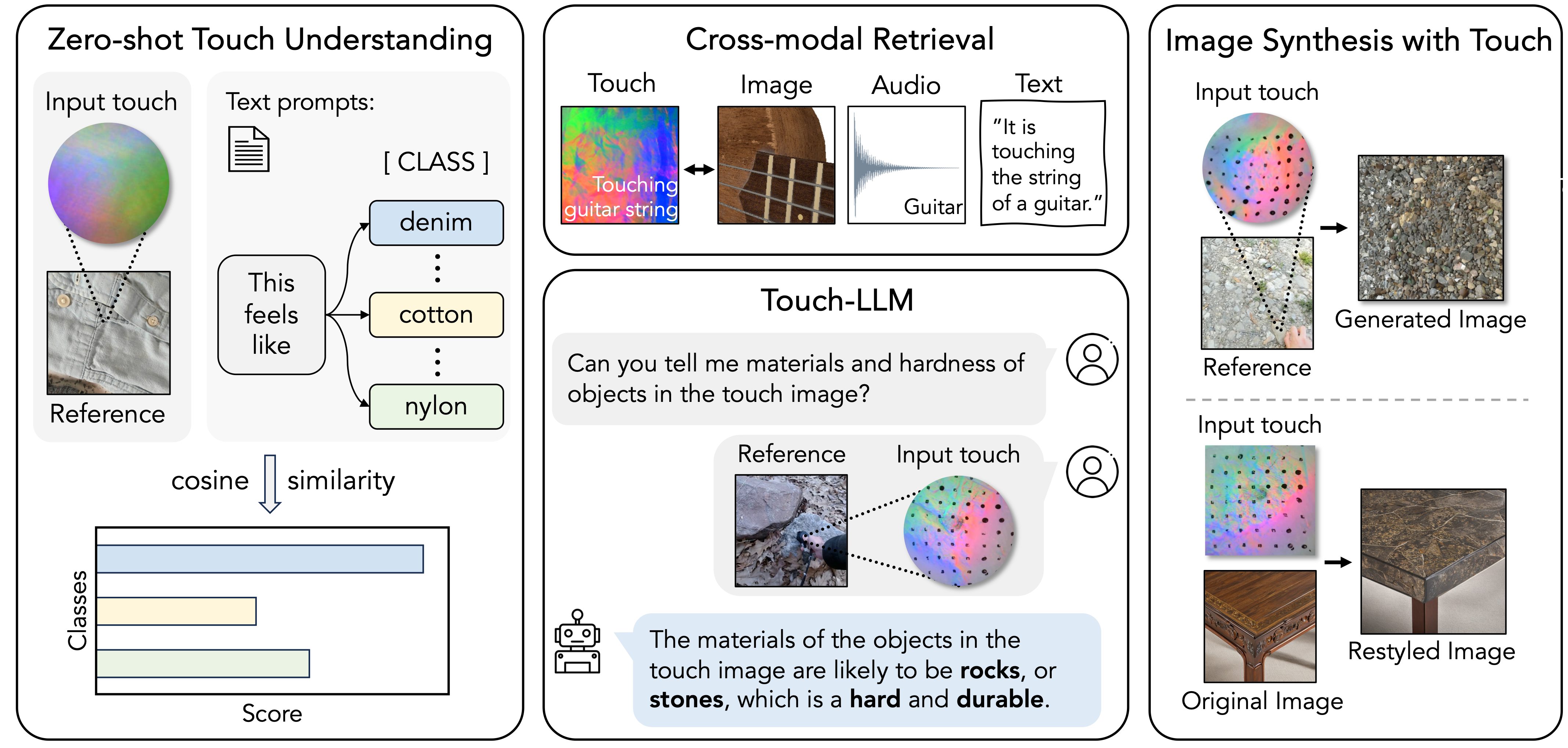
Binding Touch to Everything: Learning Unified Multimodal Tactile Representations
Fengyu Yang*, Chao Feng*, Ziyang Chen*, Hyoungseob Park, Daniel Wang, Yiming Dou, Ziyao Zeng, Xien Chen, Rit Gangopadhyay, Andrew Owens, Alex Wong, CVPR, 2024 project page / paper / code We introduce UniTouch, a unified tactile representation for vision-based tactile sensors aligned with multiple modalities. We show we can now use powerful models trained on other modalities (e.g. CLIP, LLM) to conduct tactile sensing tasks zero shot. |

|
Vision-Flan: Scaling Human-Labeled Tasks in Visual Instruction Tuning
Zhiyang Xu, Chao Feng, Rulin Shao, Trevor Ashby, Ying Shen, Di Jin, Yu Cheng, Qifan Wang, Lifu Huang, ACL, 2024 (Findings) project page / paper We construct Vision-Flan, the most diverse publicly available visual instruction tuning dataset to date. |
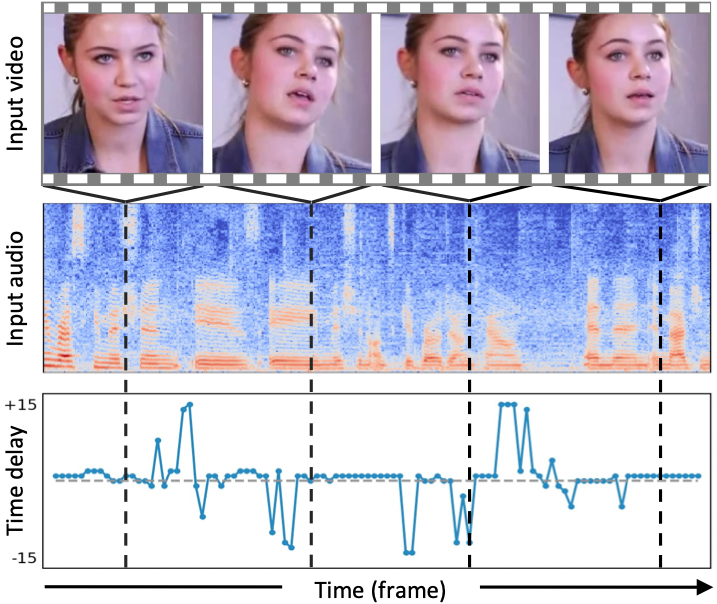
|
Chao Feng, Ziyang Chen, Andrew Owens, CVPR, 2023 (Highlight) project page / arXiv / code We learn several feature sets in a self-supervised manner by using audio-visual synchronization task and utilize autoregressive model to do anomaly detection on top of each feature set for video forensics detection. |

|
Eric Zhongcong Xu, Zeyang Song, Satoshi Tsutsui, Chao Feng, Mang Ye, Mike Zheng Shou, ACM Multimedia, 2022 project page / arXiv / code We create the AVA Audio-Visual Diarization (AVA-AVD) dataset to develop diarization methods for in-the-wild videos. |
|
CVPR 2022/2024, WACV 2023, ACM MM 2023, ICCV 2023, ECCV 2024, NeurIPS 2024, ICRA 2025, ICLR 2025, AISTATS 2025, TPAMI. |
|
|